A neural machine code and programming framework for the reservoir computer
A neural machine code and programming framework for the reservoir computer"
- Select a language for the TTS:
- UK English Female
- UK English Male
- US English Female
- US English Male
- Australian Female
- Australian Male
- Language selected: (auto detect) - EN
Play all audios:
ABSTRACT From logical reasoning to mental simulation, biological and artificial neural systems possess an incredible capacity for computation. Such neural computers offer a fundamentally
novel computing paradigm by representing data continuously and processing information in a natively parallel and distributed manner. To harness this computation, prior work has developed
extensive training techniques to understand existing neural networks. However, the lack of a concrete and low-level machine code for neural networks precludes us from taking full advantage
of a neural computing framework. Here we provide such a machine code along with a programming framework by using a recurrent neural network—a reservoir computer—to decompile, code and
compile analogue computations. By decompiling the reservoir’s internal representation and dynamics into an analytic basis of its inputs, we define a low-level neural machine code that we use
to program the reservoir to solve complex equations and store chaotic dynamical systems as random-access memory. We further provide a fully distributed neural implementation of software
virtualization and logical circuits, and even program a playable game of pong inside of a reservoir computer. Importantly, all of these functions are programmed without requiring any example
data or sampling of state space. Finally, we demonstrate that we can accurately decompile the analytic, internal representations of a full-rank reservoir computer that has been
conventionally trained using data. Taken together, we define an implementation of neural computation that can both decompile computations from existing neural connectivity and compile
distributed programs as new connections. SIMILAR CONTENT BEING VIEWED BY OTHERS PRINCIPLED NEUROMORPHIC RESERVOIR COMPUTING Article Open access 14 January 2025 REALISING AND COMPRESSING
QUANTUM CIRCUITS WITH QUANTUM RESERVOIR COMPUTING Article Open access 21 May 2021 COMPLEXITY-CALIBRATED BENCHMARKS FOR MACHINE LEARNING REVEAL WHEN PREDICTION ALGORITHMS SUCCEED AND MISLEAD
Article Open access 16 April 2024 MAIN Neural systems possess an incredible capacity for computation. From biological brains that learn to manipulate numeric symbols and run mental
simulations1,2,3 to artificial neural networks that are trained to master complex strategy games4,5, neural networks are outstanding computers. What makes these neural computers so
compelling is that they are exceptional in different ways from modern-day silicon computers: the latter relies on binary representations, rapid sequential processing6, and segregated memory
and central processing unit7, while the former utilizes continuum representations8,9, parallel and distributed processing10,11, and distributed memory12. To harness these distinct
computational abilities, prior work has studied a vast array of different network architectures13,14, learning algorithms15,16 and information-theoretic frameworks17,18,19 in both biological
and artificial neural networks. Despite these substantial advances, the relationship between neural computers and modern-day silicon computers remains an analogy due to our lack of a
concrete and low-level neural machine code, thereby limiting our access to neural computation. To bring this analogy to reality, we seek a neural network with a simple set of governing
equations that demonstrates many computer-like capabilities20. One such network is a reservoir computer (RC), which is a recurrent neural network (RNN) that receives inputs, evolves a set of
internal states forward in time and outputs a weighted sum of its states21,22. True to its namesake, RCs can be trained to perform fundamental computing functions such as memory
storage23,24 and manipulation25,26, prediction of chaotic systems22 and model-free control27. Owing to the simplicity of the governing equations, the theoretical mechanism of training is
understood, and recent advances have dramatically shortened training requirements by using a more efficient and expanded set of input training data 28. But can we skip the training
altogether and program RCs without any sampling or simulation just as we do for silicon computers? These ideas have a rich history of exploration, notably including the Neural Engineering
Framework29 and system hierarchies for brain-inspired computing30. The former defines the guiding principles—representation, transformation and dynamics—to implement complex computations and
dynamics in neuron models31. The latter defines an extension of Turing completeness to neuromorphic completeness, and builds an interface between neuromorphic software and hardware for
program-level portability. Our work sits at the intersection of these two areas by defining an extension of the former for RCs to program computations in existing RCs with full-rank
connectivity, decompile the computations performed by conventionally trained RCs and omit any sampling of state space in the optimization procedure (Supplementary Section X). Combined with
the substantial advances in experimental RC platforms32, it is now timely to formalize a programming framework to develop neural software atop RC hardware. In this Article, we provide two
such programming frameworks—state neural programming (SNP) and dynamic neural programming (DNP)—by constructing an analytic representational basis of the RC neurons, alongside two
architectures: open loop and closed loop. Through SNP, we program RCs to perform operations and solve analytic equations. Through DNP, we program RCs to store chaotic dynamical systems as
random-access memories (dRAM), virtualize the dynamics of a guest RC, implement neural logic AND, NAND, OR, NOR, XOR and XNOR, and construct neural logic circuits such as a binary adder,
flip-flop latch and multivibrator circuit. Using these circuits, we define a simple scheme for game development on RC architectures by programming an RC to simulate a variant of the game
‘pong’. Finally, we decompile computations from conventionally trained RCs as analytic functions. OPEN-LOOP ARCHITECTURE WITH SNP FOR OUTPUT FUNCTIONS We begin with the simplest
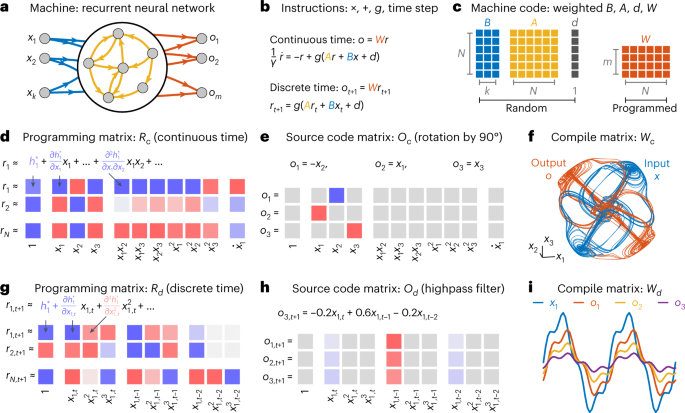
architecture, which is an open-loop neural computer architecture that treats the RNN as a function approximator. We conceptualize an RNN as a computing machine comprising _N_ neurons _R_,
which receive _k_ inputs _X_ and produce _m_ outputs _O_ (Fig. 1a). This machine typically supports the basic instructions of multiplication of the neural states and inputs by weights _A_,
_B_ and _W_, the addition of these weighted states with each other and some bias term _D_, the transformation of the resultant quantities through an activation function _g_, and evolution in
time (equations (6) and (7)). The output is given by _O_ = _W__R_ (Fig. 1b). Hence, the weights _B_, _A_, _D_ and _W_ specify the set of instructions for the RNN to run, which we
conceptualize as the low-level neural machine code (Fig. 1c). Unlike conventional computers, these instructions are simultaneously evaluated in parallel by the global set of neurons. We
randomly instantiate _B_, _A_ and _D_, and program _W_. To define a programming framework, we take the approach of translating the machine code into a representation that is meaningful to
the user. We choose that representation to be the input variables _X_, as the inputs are usually meaningful and interpretable in most applications. This translation from the low-level to the
high-level programming matrix is referred to as decompiling, and involves writing the neural states _R_ as a function _H_ of the inputs _X_ given the machine code _B_, _A_ and _D_ (Methods,
equations (8)–(10)). To write _H_ in a more understandable form, we perform a Taylor series expansion of _H_ with respect to all of the input variables
\({{{\boldsymbol{x}}}},\dot{{{{\boldsymbol{x}}}}},\cdots \,\), thereby writing the state of every neuron as a weighted sum of linear, quadratic and higher-order polynomial terms of
\({{{\boldsymbol{x}}}},\dot{{{{\boldsymbol{x}}}}},\cdots \,\). The weights that multiply these terms are precisely the coefficients of the Taylor series expansion, and form an _N_ × _K_
matrix of coefficients _R__c_, where _K_ is the number of terms in the expansion (Fig. 1d). This matrix of coefficients _R_ is our SNP matrix in the open-loop architecture. Next, we define
the source code, which is the set of programmable output functions given by the rowspace of _R_. This is because the output of our RNN is determined by a linear combination of neural states,
_W_, which are weighted sums of the _K_ expansion terms from the decompiler. Here, programming refers to specifying _m_ outputs as a weighted sum of the _K_ terms from the decompiler, which
forms an _m_ × _K_ matrix _O__c_: the source code matrix. In this example, the RNN receives three inputs: _x_1, _x_2 and _x_3. To program a 90° rotation about _x_3, we specify the
coefficients in matrix _O__c_ for three outputs _o_1, _o_2 and _o_3 (Fig. 1e). Finally, to compile the source code _O__c_ into machine code _W_, we solve
$$W=\mathop{{{{\rm{argmin}}}}}\limits_{W}\parallel WR-O\parallel .$$ (1) When we drive the RNN with the complex, chaotic time series _X_(_t_) from the Thomas attractor (Fig. 1f, blue), the
RNN output is a rotated attractor _W__R_(_t_) (Fig. 1f, orange). This process of decompiling, programming and compiling also holds in discrete-time RNNs (Fig. 1g; see Methods, equations (11)
and (12)). Our programming matrix now consists of polynomial powers of time-lagged inputs, which allows us to program operations such as highpass filters (Fig. 1h). After compiling the
program _O__d_ into _W_, the RNN outputs (Fig. 1i, orange, yellow and purple) filter away the lower-frequency components of an input signal (Fig. 1i, blue). See Supplementary Section IX for
the parameters used for all examples. CLOSED-LOOP ARCHITECTURE WITH SNP TO SOLVE ALGORITHMS To increase the computational power of these RNNs, we use the same SNP, but introduce a
closed-loop neural architecture. The idea is to use SNP to program some output function of the inputs as
\(\bar{W}{{{\boldsymbol{r}}}}={{{\boldsymbol{f}}}}(\bar{{{{\boldsymbol{x}}}}},{{{\boldsymbol{x}}}})\), and then feed that output back into the inputs to define an equivalence relation
between the outputs and the inputs to solve \(\bar{{{{\boldsymbol{x}}}}}={{{\boldsymbol{f}}}}(\bar{{{{\boldsymbol{x}}}}},{{{\boldsymbol{x}}}})\). This feedback modifies the internal
recurrent weights in the RNN, allowing it to store and modify a history of its states and inputs to store and run algorithms. Hence, the closed-loop architecture is no longer solely a
function approximator. We consider the same RNN as in Fig. 1a, except now with two sets of inputs, \(\bar{{{{\boldsymbol{x}}}}}\in {{\mathbb{R}}}^{n}\) and \({{{\boldsymbol{x}}}}\in
{{\mathbb{R}}}^{k}\), and two sets of outputs, \(\bar{{{{\boldsymbol{o}}}}}\in {{\mathbb{R}}}^{n}\) and \({{{\boldsymbol{o}}}}\in {{\mathbb{R}}}^{m}\) (Fig. 2a and equation (13)). We feed
one set of outputs back into the inputs such that \(\bar{{{{\boldsymbol{o}}}}}=\bar{{{{\boldsymbol{x}}}}}\), which will determine the internal connectivity of the RNN. Using SNP, we program
an output \(\bar{{{{\boldsymbol{o}}}}}=\bar{W}{{{\boldsymbol{r}}}}=\bar{{{{\boldsymbol{f}}}}}(\bar{{{{\boldsymbol{x}}}}},{{{\boldsymbol{x}}}})\) and perform feedback as
\(A=\bar{A}+\bar{B}\bar{W}\) (Fig. 2b,c and equation (14)). As a demonstration, we program an RNN to solve the continuous Lyapunov equation, $$I+\bar{X}+X\bar{X}+\bar{X}{X}^{\top
}=\bar{X},$$ (2) where _X_ and \(\bar{X}\) are 6 × 6 matrices such that the pre-programmed RNN receives _n_ = 36 inputs as \(\bar{{{{\boldsymbol{x}}}}}\) and _k_ = 36 inputs as _X_. Given
_X_, the solution \(\bar{X}\) to equation (2) is important for control theory33 and neuroscience34, and is often referred to as the controllability Gramian. To program equation (2) into our
RNN, we first decompile the neural states _R_ into the SNP matrix _R__c_ with respect to our input variables \(\bar{{{{\boldsymbol{x}}}}}\) and _X_ (Fig. 2d). Next, we fill in matrix _O__c_
with the coefficients of all constant, linear and quadratic terms from equation (2) (Fig. 2e). Then, we compile the program _O__c_ by solving for \({{{{\rm{argmin}}}}}_{\bar{W}}\parallel
\bar{W}{R}_{c}-{O}_{c}\parallel\), and define the recurrent connections of a new feedback RNN, \(A=\bar{A}+\bar{B}\bar{W}\), which evolves as equation (14). By driving this new RNN with a
matrix _X_, the output converges to the solution \(\bar{X}\) of equation (2) (Fig. 2f). As a demonstration for discrete-time systems, we program an RNN to store a substantial time history of
a stochastic, non-differentiable time series _x__t_, and perform a short-time Fourier transform. Starting with our decompiled RNN states (Fig. 2g), we write a program, \({\bar{O}}_{d}\), to
store time history across _n_ = 49 inputs for \({\bar{{{{\boldsymbol{x}}}}}}_{t}\), by defining a sample lag operator that shifts the state of all inputs down by one index (Fig. 2h and
equation (15)). Then, using this lagged history, we write another program, _O__d_, that outputs a short-time Fourier transform (equation (16)) with a sliding window of length _n_. We compile
these two programs by minimizing \(\parallel \bar{W}{R}_{d}-{\bar{O}}_{d}\parallel\) and ∥_W__R__d_ − _O__d_∥, and define the recurrent connectivity of a new feedback RNN—where
\(A=\bar{A}+\bar{B}\bar{W}\)—according to equation (14). By driving this RNN with a stochastic sawtooth wave of amplitude 0.2, period of eight samples and noise that is uniformly distributed
about 0 with a width of 0.1, the RNN matches the true short-time Fourier transform (for a performance comparison with conventional RCs and FORCE, see Supplementary Section VII). CLOSED-LOOP
RNN WITH DNP TO SIMULATE AND VIRTUALIZE Here we define a second, dynamical programming framework, DNP, which allows explicit programming of time history for continuous-time RNNs (for an
extended discussion, see Supplementary Section VIII). Building on SNP where we decompiled the neural states _R_, we now decompile the activation function _G_, which encodes both state and
dynamic information through a rearrangement of equation (6). We substitute \({{{\boldsymbol{r}}}}\approx {{{\boldsymbol{h}}}}(\bar{{{{\boldsymbol{x}}}}},{{{\boldsymbol{x}}}})\) into equation
(13) as $${{{\boldsymbol{r}}}}+\frac{1}{\gamma
}\dot{{{{\boldsymbol{r}}}}}={{{\boldsymbol{g}}}}(A{{{\boldsymbol{h}}}}(\bar{{{{\boldsymbol{x}}}}},{{{\boldsymbol{x}}}})+\bar{B}\bar{{{{\boldsymbol{x}}}}}+B{{{\boldsymbol{x}}}}+{{{\boldsymbol{d}}}}).$$
(3) Hence, our DNP decompiler takes the Taylor series coefficients of _G_ instead of _H_, allowing us to program not only output functions of the input states, but also the input time
history. As a demonstration, we consider an RNN with 15 states, \({{{{\boldsymbol{r}}}}}^{\circ }\in {{\mathbb{R}}}^{15}\), which receives three inputs \(\bar{{{{\boldsymbol{x}}}}}\in
{{\mathbb{R}}}^{3}\). We will use the closed-loop architecture where \({\bar{A}}^{\circ }\), \({\bar{B}}^{\circ }\) and _D_∘ are randomly initialized, which is decompiled according to
equation (3) (Fig. 3a). Because our decompiled code consists of analytic state and time-derivative variables, we can compile \({\bar{W}}^{\circ }\) to map RNN states to input states, and RNN
time derivatives to input time derivatives. Prior work has trained RNNs to simulate time-evolving systems by copying exemplars22 or sampling the dynamical state space35. Here we achieve the
same simulation without any samples in a chaotic Lorenz attractor that evolves according to \(\dot{\bar{{{{\boldsymbol{x}}}}}}=f(\bar{{{{\boldsymbol{x}}}}})\), such that
$$\bar{W}{{{\boldsymbol{g}}}}(\bar{{{{\boldsymbol{x}}}}})=\bar{W}\left({{{\boldsymbol{r}}}}+\frac{1}{\gamma }\dot{{{{\boldsymbol{r}}}}}\right)=\bar{{{{\boldsymbol{x}}}}}+\frac{1}{\gamma
}\dot{\bar{{{{\boldsymbol{x}}}}}}=\bar{{{{\boldsymbol{x}}}}}+\frac{1}{\gamma }\,f(\bar{{{{\boldsymbol{x}}}}}).$$ (4) Here, ‘programming’ refers to the construction of a matrix
\({\bar{O}}_{c}^{\circ }\) comprising the coefficients of \(\bar{{{{\boldsymbol{x}}}}}+\frac{1}{\gamma }\,f(\bar{{{{\boldsymbol{x}}}}})\) preceding the variables
\(1,{\bar{x}}_{1},{\bar{x}}_{2},{\bar{x}}_{3},{\bar{x}}_{1}{\bar{x}}_{2},\cdots \,\) of the program matrix \({G}_{c}^{\circ }\) (Fig. 3b). Once we compile this code and perform feedback by
defining new connectivity \(A=\bar{A}+\bar{B}\bar{W}\), the evolution of the RNN simulates the Lorenz attractor (Fig. 3c). More generally, DNP allows us to program systems of the form
\(\dot{\bar{{{{\boldsymbol{x}}}}}}=f(\bar{{{{\boldsymbol{x}}}}})\), which raises an interesting phenomenon. We program another RNN \({{{\boldsymbol{r}}}}\in {{\mathbb{R}}}^{2000}\)—the
host—to emulate the dynamics of the feedback RNN \({{{{\boldsymbol{r}}}}}^{\circ }\in {{\mathbb{R}}}^{15}\)—the guest—that itself was programmed to evolve about the Lorenz attractor. We
decompile the host RNN using DNP (Fig. 3d), write the code of the guest RNN in the format \({{{{\boldsymbol{r}}}}}^{\circ }+\frac{1}{\gamma }{\dot{{{{\boldsymbol{r}}}}}}^{\circ }\) (Fig.
3e), and compile the code into matrix \(\bar{W}\) (Fig. 3f). The 2,000 state host RNN emulates the 15 state guest RNN, which is simulating a Lorenz attractor. A larger host can emulate
multiple guests as a virtual machine36. OP-CODES, COMPOSITION AND DYNAMIC RAM Here we extend more of the functionality of general purpose computers to RNNs. The first functionality is
support for op-codes, which is typically a string of bits specifying which instruction to run. We add control inputs _C_ as a string of 0s and 1s such that $$\frac{1}{\gamma
}\dot{{{{\boldsymbol{r}}}}}=-{{{\boldsymbol{r}}}}+{{{\boldsymbol{g}}}}(\bar{A}{{{\boldsymbol{r}}}}+\bar{B}\bar{{{{\boldsymbol{x}}}}}+B{{{\boldsymbol{x}}}}+C{{{\boldsymbol{c}}}}+{{{\boldsymbol{d}}}}),$$
which pushes the pre-programmed RNN to different fixed points, thereby generating a unique SNP at each point (Fig. 4a). Then, we program different matrix operations (Fig. 4b), and
simultaneously compile each source code at a different SNP (Fig. 4c) into matrix \(\bar{W}\). When we drive our RNN with matrices _P_ and _Q_ at different _C_, the RNN outputs each operation
(Fig. 4d). The second functionality is the ability to compose more complicated programs from simpler programs. We note that, in SNP, the output is programmed and compiled to perform an
operation on the inputs, such as a matrix multiplication and vector addition for a neural processing unit (NPU, Fig. 4e). By feeding these outputs into another NPU, we can perform a
successive series of feedback operations to define and solve more complex equations, such as least-squares regression (NPU, Fig. 4e). The third functionality is the random access of chaotic
dynamical memories. The control inputs _C_ drive the RNN to different fixed points, thereby generating unique DNPs \({G}_{{c}_{1},{c}_{2}}\) (Fig. 4f). By compiling a single matrix _W_ that
maps each DNP to a unique attractor (Fig. 4g,h), the feedback RNN with internal connectivity \(A=\bar{A}+\bar{B}\bar{W}\) autonomously evolves about each of the four chaotic attractors at
different values of _C_ (Fig. 4i). A LOGICAL CALCULUS USING RECURRENT NEURAL CIRCUITS This dynamical programming framework allows us to greatly expand the computational capability of our
RNNs by programming neural implementations of logic gates. While prior work has established the ability of biological and artificial networks to perform computations, here we provide an
implementation that makes full use of existing computing frameworks. We program logic gates into distributed RNNs by using a simple dynamical system $$\dot{x}=a{x}^{3}+bx+z,$$ (5) where _a_,
_b_ and _z_ are parameters. This particular system has the nice property of hysteresis, where when _z_ = 0.1, the value of _x_ converges to _x_ = 0.1, but when _z_ = −0.1, the value of _x_
jumps discontinuously to converge at _x_ = −0.1 (Fig. 5a). This property enables us to program logic gates (Fig. 5b). Specifically, by defining the variable _z_ as a product of two input
variables _p_ and _q_, we can program in the dynamics in equation (5) to evolve to −0.1 or 0.1 for different patterns of _p_ and _q_. These logic gates can now take full advantage of
existing computing frameworks. For example, we can construct a full adder using neural circuits that take Boolean values _p_ and _q_ as the two numbers to be added, and a ‘carry’ value from
the previous addition operation. The adder outputs the sum _s_ and the output carry _v_. We show the inputs and outputs of a fully neural adder in Fig. 5c, forming the basis of our ability
to program neural logic units, which are neural analogues of existing arithmetic logic units. The emulation of these neural logic gates to circuit design extends even to recurrent circuit
architectures. For example, the set–reset (SR) latch—commonly referred to as a flip-flop—is a circuit that holds persistent memory, and is used extensively in computer random-access memory
(RAM). We construct a neural SR latch using two NOR gates with two inputs, _p_ and _q_ (Fig. 5d). When _p_ = 0.1 is pulsed high, the output _o_ = − 0.1 changes to low. When _q_ is pulsed
high, the output changes to high. When both _p_ and _q_ are held low, then the output is fixed at its most recent value (Fig. 5d). As another example, we can chain an odd number of inverting
gates (that is, NAND, NOR and XOR) to construct a multivibrator circuit that generates oscillations (Fig. 5e). Because the output of each gate will be the inverse of its input, if _p_ is
high, then _q_ is low and _o_ is high. However, if we use _o_ as the input to the first gate, then _p_ must switch to low. This discrepancy produces constant fluctuations in the states of
_p_, _q_ and _o_, which generate oscillations that are offset by the same phase (Fig. 5e). GAME DEVELOPMENT AND DECOMPILING TRAINED RNNS To demonstrate the flexibility and capacity of our
framework, we program a variant of the game ‘pong’ into our RNN as a dynamical system. We begin with the game design by defining the relevant variables and behaviours (Fig. 6a). The
variables are the coordinates of the ball, _x_, _y_, the velocity of the ball, \(\dot{x},\dot{y}\), and the position of the paddle, _x_p. Additionally, we have the variables that determine
contact with the left, right and upper walls as _c_l, _c_r and _c_u, respectively, and the variable that determines contact with the paddle, _c_p. The behaviour that we want is for the ball
to travel with a constant velocity until it hits either a wall or the paddle, at which point the ball should reverse direction. Here we run into our first problem: how do we represent
contact detection—a fundamentally discontinuous behaviour—using continuous dynamics? Recall that we have already done so to program logic gates in Fig. 5a by using the bifurcation of the
cubic dynamical system in equation (5). Here we will use the exact same equation, except rather than changing the parameter _z_ to shift the dynamics up and down (Fig. 5a), we will set the
parameter _b_ to skew the shape. As an example, for the right-wall contact _c_r, we will let _b_ = _x_ − _x_r (Fig. 6b). When the ball is to the left such that _x_ < _x_r, then _c_r
approaches 0. When the ball is to the right such that _x_ > _x_r, then _c_r becomes non-zero. To set the velocity of the ball, we use the SR latch developed in Fig. 5d. When neither wall
is in contact, then _c_r and _c_l are both low, and the latch’s output does not change. When either the right or the left wall is in contact, then either _c_r or _c_l pulses the latch,
producing a shift in the velocity (Fig. 6c). Combining these dynamical equations together produces the code for our pong program (Fig. 6d), and the time evolution of our programmed RNN
simulates a game of pong (Fig. 6e). To demonstrate the capacity of our programming framework beyond compiling programs, we decompile the internal representation of a reservoir that has been
trained to perform an operation. We instantiate a reservoir with random input matrix _B_ and random recurrent matrix _A_, drive the reservoir with a sum of sinusoids—thereby generating a
time series _R_(_t_)—and train the output weights _W_ to reconstruct highpass-filtered versions of the inputs (Fig. 6f). To understand what the reservoir has learned, we decompile the
reservoir state given _A_ and _B_ into the SNP matrix _R__d_ according to equation (12), and find that the output _W__R__d_ as an analytic function of the inputs and time derivatives closely
matches the true filter coefficients (Fig. 6g). DISCUSSION Neural computation exists simultaneously at the core of and the intersection between many fields of study. From the differential
binding of neurexins in molecular biology37 and neural circuits in neuroscience38,39,40,41,42, to the RNNs in dynamical systems43 and neural replicas of computer architectures in machine
learning44, the analogy between neural and silicon computers has generated growing and interdisciplinary interest. Our work provides one possible realization of this analogy by defining a
dynamical programming framework for RNNs that takes full advantage of their natively continuous and analytic representation, their parallel and distributed processing, and their dynamical
evolution. This work also makes an important contribution to the increasing interest in alternative computation. A clear example is the vast array of systems—such as molecular45, DNA46 and
single photon47—that implement Boolean logic gates. Other examples include the design of materials that compute48,49 and store memories50,51. Perhaps of most relevance are physical
instantiations of reservoir computing in electronic, photonic, mechanical and biological systems32. Our work demonstrates the potential of alternative computing frameworks to be fully
programmable, thereby shifting paradigms away from imitating silicon computer hardware6, and towards defining native programming frameworks that bring out the full computational capability
of each system. One of the main current limitations is the linear approximation of the RC dynamics. While prior work demonstrates substantial computational ability for RCs with largely
fluctuating dynamics (that is, computation at the edge of chaos52), the approximation used in this work requires that the RC states stay reasonably close to the operating points. While we
are able to program a single RC at multiple operating points that are far apart, the linearization is a prominent limitation. Future extensions would use more advanced dynamical
approximations into the bilinear regime using Volterra kernels53 or Koopman composition operators54 to better capture non-linear behaviours. Finally, we report in the Supplementary Section
XI an analysis of the gender and the racial makeup of the authors we cited in a Citation Diversity Statement. METHODS OPEN-LOOP ARCHITECTURE WITH SNP In our framework, we conceptualize an
RNN comprising _N_ neurons \({{{\boldsymbol{r}}}}\in {{\mathbb{R}}}^{N}\), which receive _k_ inputs \({{{\boldsymbol{x}}}}\in {{\mathbb{R}}}^{k}\) and produce _m_ outputs
\({{{\boldsymbol{o}}}}\in {{\mathbb{R}}}^{m}\). This machine has weights \(A\in {{\mathbb{R}}}^{N\times N}\), \(B\in {{\mathbb{R}}}^{N\times k}\), and \(W\in {{\mathbb{R}}}^{m\times N}\),
and some bias term \({{{\boldsymbol{d}}}}\in {{\mathbb{R}}}^{N\times 1}\). If the RNN evolves in continuous time, the instructions are $$\frac{1}{\gamma
}\dot{{{{\boldsymbol{r}}}}}(t)=-{{{\boldsymbol{r}}}}(t)+{{{\boldsymbol{g}}}}(A{{{\boldsymbol{r}}}}(t)+B{{{\boldsymbol{x}}}}(t)+{{{\boldsymbol{d}}}}),$$ (6) where 1/_γ_ is a time constant. If
the RNN evolves in discrete time, these instructions are $${{{{\boldsymbol{r}}}}}_{t+1}={{{\boldsymbol{g}}}}(A{{{{\boldsymbol{r}}}}}_{t}+B{{{{\boldsymbol{x}}}}}_{t}+{{{\boldsymbol{d}}}}).$$
(7) We decompile the neural states _R_ as a function _H_ of the inputs _X_ given the machine code _B_, _A_ and _D_ in three steps. First, we linearize the dynamics in equation (6) about a
stable fixed point _R_* and an operating point _X_* to yield $$\begin{array}{r}\frac{1}{\gamma }\dot{{{{\boldsymbol{r}}}}}(t)\approx {A}^{*
}{{{\boldsymbol{r}}}}(t)+\underbrace{{{{\boldsymbol{g}}}(A{{{{\boldsymbol{r}}}}}^{*
}+B{{{\boldsymbol{x}}}}(t)+{{{\boldsymbol{d}}}})-{{{\rm{d}}}}{{{\boldsymbol{g}}}}(A{{{{\boldsymbol{r}}}}}^{* }+B{{{\boldsymbol{x}}}}(t)+{{{\boldsymbol{d}}}})\circ A{{{{\boldsymbol{r}}}}}^{*
}}}_{\begin{array}{c}{{{\boldsymbol{u}}}}({{{\boldsymbol{x}}}}(t))\end{array}},\end{array}$$ (8) where _A_* = (d_G_(_A__R_* + _B__X_* + _D_)∘_A_ − _I_). Second, because our system is now
linear, we can write the neural states as the convolution of the impulse response and the inputs as $${{{\boldsymbol{r}}}}(t)\approx \gamma \int\nolimits_{-\infty }^{t}{e}^{\gamma {A}^{*
}(t-\tau )}{{{\boldsymbol{u}}}}({{{\boldsymbol{x}}}}(\tau )){{{\rm{d}}}}\tau .$$ (9) Third, to obtain _R_(_t_) as an algebraic function without an integral, we perform a Taylor series
expansion of this convolution with respect to _t_ to yield $${{{\boldsymbol{r}}}}(t)\approx
{{{\boldsymbol{h}}}}({{{\boldsymbol{x}}}}(t),\dot{{{{\boldsymbol{x}}}}}(t),\ddot{{{{\boldsymbol{x}}}}}(t),\cdots \,).$$ (10) We provide a detailed analytical derivation of _H_ in the
Supplementary Sections I–III, and demonstrate the goodness of the approximations in Supplementary Sections IV–VI. To decompile discrete-time RNNs, first we linearize equation (7) about a
stable fixed point _R_* and operating point _X_*: $$\begin{array}{r}{{{{\boldsymbol{r}}}}}_{t+1}={A}^{* }{{{{\boldsymbol{r}}}}}_{t}+\underbrace{{{{\boldsymbol{g}}}(A{{{{\boldsymbol{r}}}}}^{*
}+B{{{{\boldsymbol{x}}}}}_{t}+{{{\boldsymbol{d}}}})-{{{\rm{d}}}}{{{\boldsymbol{g}}}}(A{{{{\boldsymbol{r}}}}}^{* }+B{{{{\boldsymbol{x}}}}}_{t}+{{{\boldsymbol{d}}}})\circ
A{{{{\boldsymbol{r}}}}}^{* }}}_{\begin{array}{c}{{{\boldsymbol{u}}}}({{{{\boldsymbol{x}}}}}_{t})\end{array}},\end{array}$$ (11) where _A_* = d_G_(_A__R_* + _B__X_* + _D_)∘_A_. Second, we
write _R__t_+1 as the convolved sum of inputs $${{{{\boldsymbol{r}}}}}_{t+1}=\mathop{\sum }\limits_{n=0}^{t}{A}^{*
n}{{{\boldsymbol{u}}}}({{{{\boldsymbol{x}}}}}_{t-n})={{{\boldsymbol{h}}}}({{{{\boldsymbol{x}}}}}_{t},{{{{\boldsymbol{x}}}}}_{t-1},\cdots \,),$$ (12) which we Taylor series expand to yield
the _N_ × _K_ coefficient matrix for _K_ expansion terms. CLOSED-LOOP ARCHITECTURE WITH SNP For the closed-loop architecture with SNP, we begin with the pre-programmed RNNs,
$$\frac{1}{\gamma
}\dot{{{{\boldsymbol{r}}}}}=-{{{\boldsymbol{r}}}}+{{{\boldsymbol{g}}}}(\bar{A}{{{\boldsymbol{r}}}}+\bar{B}\bar{{{{\boldsymbol{x}}}}}+B{{{\boldsymbol{x}}}}+{{{\boldsymbol{d}}}}),{{{{\boldsymbol{r}}}}}_{t+1}={{{\boldsymbol{g}}}}(\bar{A}{{{{\boldsymbol{r}}}}}_{t}+\bar{B}{\bar{{{{\boldsymbol{x}}}}}}_{t}+B{{{{\boldsymbol{x}}}}}_{t}+{{{\boldsymbol{d}}}}),$$
(13) for continuous-time and discrete-time systems, respectively (Fig. 2b). Using SNP, we program an output
\(\bar{{{{\boldsymbol{o}}}}}=\bar{W}{{{\boldsymbol{r}}}}=\bar{{{{\boldsymbol{f}}}}}(\bar{{{{\boldsymbol{x}}}}},{{{\boldsymbol{x}}}})\) and perform feedback as \(A=\bar{A}+\bar{B}\bar{W}\) to
yield $$\frac{1}{\gamma
}\dot{{{{\boldsymbol{r}}}}}=-{{{\boldsymbol{r}}}}+{{{\boldsymbol{g}}}}((\bar{A}+\bar{B}\bar{W}){{{\boldsymbol{r}}}}+B{{{\boldsymbol{x}}}}+{{{\boldsymbol{d}}}}),{{{{\boldsymbol{r}}}}}_{t+1}={{{\boldsymbol{g}}}}((\bar{A}+\bar{B}\bar{W}){{{{\boldsymbol{r}}}}}_{t}+B{{{{\boldsymbol{x}}}}}_{t}+{{{\boldsymbol{d}}}}),$$
(14) for continuous-time and discrete-time systems, respectively. The sample lag operator is defined as
$${\bar{o}}_{i,t+1}=\bar{f}({\bar{{{{\boldsymbol{x}}}}}}_{t},{x}_{t})=\left\{\begin{array}{ll}{\bar{x}}_{i+1,t}&1\le i < n\\ {x}_{t}&i=n,\end{array}\right.$$ (15) which shifts the
state of all inputs down by one index. The short-time Fourier transform with a sliding window of length _n_ is defined as $${o}_{i,t+1}=\mathop{\sum }\limits_{j=0}^{n-1}\cos
\left(\frac{2\pi ij}{n}\right){\bar{x}}_{j+1,t},{o}_{i+n,t+1}=\mathop{\sum }\limits_{j=0}^{n-1}\sin \left(\frac{2\pi ij}{n}\right){\bar{x}}_{j+1,t}.$$ (16) DATA AVAILABILITY There are no
data with mandated deposition used in the manuscript or supplement. All data in the main text and Supplementary Information are generated by the code that is publicly available online. CODE
AVAILABILITY All figures were directly generated in MATLAB from the code available on Code Ocean, available upon publication at https://codeocean.com/capsule/7809611/tree/v1 (ref. 55).
CHANGE HISTORY * _ 28 JUNE 2023 A Correction to this paper has been published: https://doi.org/10.1038/s42256-023-00693-7 _ REFERENCES * Nieder, A. & Dehaene, S. Representation of number
in the brain. _Annu. Rev. Neurosci._ 32, 185–208 (2009). Article Google Scholar * Salmelin, R., Hari, R., Lounasmaa, O. V. & Sams, M. Dynamics of brain activation during picture
naming. _Nature_ 368, 463–465 (1994). Article Google Scholar * Hegarty, M. Mechanical reasoning by mental simulation. _Trends Cogn. Sci._ 8, 280–285 (2004). Article Google Scholar *
Silver, D. et al. Mastering the game of Go with deep neural networks and tree search. _Nature_ 529, 484–489 (2016). Article Google Scholar * Silver, D. et al. Mastering the game of Go
without human knowledge. _Nature_ 550, 354–359 (2017). Article Google Scholar * Patterson, D. A. & Hennessy, J. L. _Computer Organization and Design ARM Edition: The Hardware Software
Interface_ (Morgan Kaufmann, 2016). * Von Neumann, J. First draft of a report on the EDVAC. _IEEE Ann. Hist. Comput._ 15, 27–75 (1993). Article MathSciNet MATH Google Scholar * Singh, C.
& Levy, W. B. A consensus layer V pyramidal neuron can sustain interpulse-interval coding. _PLoS ONE_ 12, e0180839 (2017). Article Google Scholar * Gollisch, T. & Meister, M.
Rapid neural coding in the retina with relative spike latencies. _Science_ 319, 1108–1111 (2008). Article Google Scholar * Sigman, M. & Dehaene, S. Brain mechanisms of serial and
parallel processing during dual-task performance. _J. Neurosci._ 28, 7585–7598 (2008). Article Google Scholar * Nassi, J. J. & Callaway, E. M. Parallel processing strategies of the
primate visual system. _Nat. Rev. Neurosci._ 10, 360–372 (2009). Article Google Scholar * Rissman, J. & Wagner, A. D. Distributed representations in memory: insights from functional
brain imaging. _Annu. Rev. Psychol._ 63, 101–128 (2012). Article Google Scholar * Cho, K., Van Merriënboer, B., Bahdanau, D. & Bengio, Y. On the properties of neural machine
translation: encoder–decoder approaches. _Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation_ 103–111 (2014). * Towlson, E. K., Vértes, P.
E., Ahnert, S. E., Schafer, W. R. & Bullmore, E. T. The rich club of the _C. elegans_ neuronal connectome. _J. Neurosci._ 33, 6380–6387 (2013). Article Google Scholar * Werbos, P. J.
Backpropagation through time: what it does and how to do it. _Proc. IEEE_ 78, 1550–1560 (1990). Article Google Scholar * Caporale, N. & Dan, Y. Spike timing–dependent plasticity: a
Hebbian learning rule. _Annu. Rev. Neurosci._ 31, 25–46 (2008). Article Google Scholar * Tishby, N., Pereira, F. C. & Bialek, W. The information bottleneck method. Preprint at _arXiv_
https://doi.org/10.48550/arXiv.physics/0004057 (2000). * Olshausen, B. A. & Field, D. J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images.
_Nature_ 381, 607–609 (1996). Article Google Scholar * Kline, A. G. & Palmer, S. Gaussian information bottleneck and the non-perturbative renormalization group. _New J. Phys._ 24,
033007 (2021). Article MathSciNet Google Scholar * Lukoševičius, M., Jaeger, H. & Schrauwen, B. Reservoir computing trends. _Künstl. Intell._ 26, 365–371 (2012). Article Google
Scholar * Jaeger, H. The “echo state” approach to analysing and training recurrent neural networks—with an erratum note. _Bonn, Germany: German National Research Center for Information
Technology GMD Technical Report_ 148, 13 (2001). Google Scholar * Sussillo, D. & Abbott, L. F. Generating coherent patterns of activity from chaotic neural networks. _Neuron_ 63,
544–557 (2009). Article Google Scholar * Lu, Z., Hunt, B. R. & Ott, E. Attractor reconstruction by machine learning. _Chaos_ 28, 061104 (2018). Article MathSciNet Google Scholar *
Kocarev, L. & Parlitz, U. Generalized synchronization, predictability, and equivalence of unidirectionally coupled dynamical systems. _Phys. Rev. Lett._ 76, 1816 (1996). Article Google
Scholar * Smith, L. M., Kim, J. Z., Lu, Z. & Bassett, D. S. Learning continuous chaotic attractors with a reservoir computer. _Chaos_ 32, 011101 (2022). Article Google Scholar * Kim,
J. Z., Lu, Z., Nozari, E., Pappas, G. J. & Bassett, D. S. Teaching recurrent neural networks to infer global temporal structure from local examples. _Nat. Mach. Intell._ 3, 316–323
(2021). Article Google Scholar * Canaday, D., Pomerance, A. & Gauthier, D. J. Model-free control of dynamical systems with deep reservoir computing. _J. Phys. Complex._ 2, 035025
(2021). Article Google Scholar * Gauthier, D. J., Bollt, E., Griffith, A. & Barbosa, W. A. Next generation reservoir computing. _Nat. Commun._ 12, 5564 (2021). Article Google Scholar
* Eliasmith, C. & Anderson, C. H. _Neural Engineering: Computation, Representation, and Dynamics in Neurobiological Systems_ (MIT Press, 2003). * Zhang, Y. et al. A system hierarchy
for brain-inspired computing. _Nature_ 586, 378–384 (2020). Article Google Scholar * Eliasmith, C. et al. A large-scale model of the functioning brain. _Science_ 338, 1202–1205 (2012).
Article Google Scholar * Tanaka, G. et al. Recent advances in physical reservoir computing: a review. _Neural Netw._ 115, 100–123 (2019). Article Google Scholar * Pasqualetti, F.,
Zampieri, S. & Bullo, F. Controllability metrics, limitations and algorithms for complex networks. _IEEE Trans. Control Netw. Syst._ 1, 40–52 (2014). Article MathSciNet MATH Google
Scholar * Karrer, T. M. et al. A practical guide to methodological considerations in the controllability of structural brain networks. _J. Neural Eng._ 17, 026031 (2020). Article Google
Scholar * Bekolay, T. et al. Nengo: a Python tool for building large-scale functional brain models. _Front. Neuroinform._ 7, 48 (2014). Article Google Scholar * Rosenblum, M. &
Garfinkel, T. Virtual machine monitors: current technology and future trends. _Computer_ 38, 39–47 (2005). Article Google Scholar * Südhof, T. C. Synaptic neurexin complexes: a molecular
code for the logic of neural circuits. _Cell_ 171, 745–769 (2017). Article Google Scholar * Lerner, T. N., Ye, L. & Deisseroth, K. Communication in neural circuits: tools,
opportunities, and challenges. _Cell_ 164, 1136–1150 (2016). Article Google Scholar * Feller, M. B. Spontaneous correlated activity in developing neural circuits. _Neuron_ 22, 653–656
(1999). Article Google Scholar * Calhoon, G. G. & Tye, K. M. Resolving the neural circuits of anxiety. _Nat. Neurosci._ 18, 1394–1404 (2015). Article Google Scholar * Maass, W.,
Joshi, P. & Sontag, E. D. Computational aspects of feedback in neural circuits. _PLoS Comput. Biol._ 3, e165 (2007). Article MathSciNet Google Scholar * Clarke, L. E. & Barres, B.
A. Emerging roles of astrocytes in neural circuit development. _Nat. Rev. Neurosci._ 14, 311–321 (2013). Article Google Scholar * Sussillo, D. Neural circuits as computational dynamical
systems. _Curr. Opin. Neurobiol._ 25, 156–163 (2014). Article Google Scholar * Graves, A. et al. Hybrid computing using a neural network with dynamic external memory. _Nature_ 538, 471–476
(2016). Article Google Scholar * Kompa, K. & Levine, R. A molecular logic gate. _Proc. Natl Acad. Sci. USA_ 98, 410–414 (2001). Article Google Scholar * Zhang, M. & Ye, B.-C. A
reversible fluorescent DNA logic gate based on graphene oxide and its application for iodide sensing. _Chem. Commun._ 48, 3647–3649 (2012). Article Google Scholar * Pittman, T., Fitch, M.,
Jacobs, B. & Franson, J. Experimental controlled–not logic gate for single photons in the coincidence basis. _Phys. Rev. A_ 68, 032316 (2003). Article Google Scholar * Fang, Y.,
Yashin, V. V., Levitan, S. P. & Balazs, A. C. Pattern recognition with “materials that compute”. _Sci. Adv._ 2, e1601114 (2016). Article Google Scholar * Stern, M., Hexner, D., Rocks,
J. W. & Liu, A. J. Supervised learning in physical networks: from machine learning to learning machines. _Phys. Rev. X_ 11, 021045 (2021). Google Scholar * Pashine, N., Hexner, D., Liu,
A. J. & Nagel, S. R. Directed aging, memory, and nature’s greed. _Sci. Adv._ 5, eaax4215 (2019). Article Google Scholar * Chen, T., Pauly, M. & Reis, P. M. A reprogrammable
mechanical metamaterial with stable memory. _Nature_ 589, 386–390 (2021). Article Google Scholar * Boedecker, J., Obst, O., Lizier, J. T., Mayer, N. M. & Asada, M. Information
processing in echo state networks at the edge of chaos. _Theory Biosci._ 131, 205–213 (2012). Article Google Scholar * Svoronos, S., Stephanopoulos, G. & Aris, R. Bilinear
approximation of general non-linear dynamic systems with linear inputs. _Int. J. Control_ 31, 109–126 (1980). Article MATH Google Scholar * Bevanda, P., Sosnowski, S. & Hirche, S.
Koopman operator dynamical models: learning, analysis and control. _Annu. Rev. Control_ 52, 197–212 (2021). Article MathSciNet Google Scholar * Kim, J. Z. & Bassett, D. S. A neural
machine code and programming framework for the reservoir computer. _Code Ocean_ https://doi.org/10.24433/CO.7077387.v1 (2023). Download references ACKNOWLEDGEMENTS We gratefully acknowledge
M. X. Lim, K. A. Murphy, H. Ju, D. Zhou and J. Stiso for conversations and comments on the manuscript. J.Z.K. acknowledges support from the National Science Foundation Graduate Research
Fellowship No. DGE-1321851, and the Cornell Bethe/KIC/Wilkins Theory Postdoctoral Fellowship. D.S.B. acknowledges support from the John D. and Catherine T. MacArthur Foundation, the ISI
Foundation, the Alfred P. Sloan Foundation, an NSF CAREER award PHY-1554488, and the NSF through the University of Pennsylvania Materials Research Science and Engineering Center (MRSEC)
DMR-1720530. AUTHOR INFORMATION AUTHORS AND AFFILIATIONS * Department of Bioengineering, University of Pennsylvania, Philadelphia, PA, USA Jason Z. Kim * Department of Physics, Cornell
University, Ithaca, NY, USA Jason Z. Kim * Departments of Bioengineering, Physics & Astronomy, Electrical & Systems Engineering, Neurology, and Psychiatry, University of
Pennsylvania, Philadelphia, PA, USA Dani S. Bassett * Santa Fe Institute, Santa Fe, NM, USA Dani S. Bassett Authors * Jason Z. Kim View author publications You can also search for this
author inPubMed Google Scholar * Dani S. Bassett View author publications You can also search for this author inPubMed Google Scholar CONTRIBUTIONS J.Z.K. conceived the initial idea and
developed the analyses in conversation with D.S.B. J.Z.K. and D.S.B. prepared the manuscript. All authors contributed to discussions and approved the manuscript. CORRESPONDING AUTHOR
Correspondence to Dani S. Bassett. ETHICS DECLARATIONS COMPETING INTERESTS The authors declare no competing interests. PEER REVIEW PEER REVIEW INFORMATION _Nature Machine Intelligence_
thanks Adrian Valente, Brian DePasquale and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. ADDITIONAL INFORMATION PUBLISHER’S NOTE Springer Nature
remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. SUPPLEMENTARY INFORMATION SUPPLEMENTARY INFORMATION Supplementary Figs. 1–12,
discussion and derivations of equations. RIGHTS AND PERMISSIONS OPEN ACCESS This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use,
sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative
Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated
otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds
the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/. Reprints and
permissions ABOUT THIS ARTICLE CITE THIS ARTICLE Kim, J.Z., Bassett, D.S. A neural machine code and programming framework for the reservoir computer. _Nat Mach Intell_ 5, 622–630 (2023).
https://doi.org/10.1038/s42256-023-00668-8 Download citation * Received: 28 April 2022 * Accepted: 26 April 2023 * Published: 12 June 2023 * Issue Date: June 2023 * DOI:
https://doi.org/10.1038/s42256-023-00668-8 SHARE THIS ARTICLE Anyone you share the following link with will be able to read this content: Get shareable link Sorry, a shareable link is not
currently available for this article. Copy to clipboard Provided by the Springer Nature SharedIt content-sharing initiative
Trending News
Unidirectional luminescence from ingan/gan quantum-well metasurfacesABSTRACT III–nitride light-emitting diodes (LEDs) are the backbone of ubiquitous lighting and display applications. Impa...
Jonny bairstow axed from england test squad for tour to new zealandEngland have left out Jonny Bairstow from their 15-man squad for the two Tests against New Zealand, starting on November...
Javascript support required...
Deshotel bill would scrap testing as graduation requirementEducation leaders in the House and Senate each have competing plans to scale back Texas’ school testing requirements and...
Nintendo switch 2 fans can get the new console right now from very and nintendoTHE NINTENDO SWITCH 2 IS DUE TO BE RELEASED IN THE UK ON JUNE 5, AND STOCK HAS BEEN TRICKLING IN FOR RETAILERS 10:20, 22...
Latests News
A neural machine code and programming framework for the reservoir computerABSTRACT From logical reasoning to mental simulation, biological and artificial neural systems possess an incredible cap...
How lululemon got kicked in the (butt-baring) pantsLululemon Athletica is having a tough week. The Vancouver-based maker of yoga-wear reported fourth-quarter results that ...
Decoding calcium signals involved in cardiac growth and functionABSTRACT Calcium is central in the regulation of cardiac contractility, growth and gene expression. Variations in the am...
Existence is disputable | Nature AstronomyKepler-1625b-I and Kepler-1708b-I are the most noteworthy exomoon candidates to date. A new analysis of the available da...
404 Not Found!You're using an Ad-Blocker. BeforeItsNews only exists through ads.We ask all patriots who appreciate the evil we expose ...