Joint stereo 3d object detection and implicit surface reconstruction
Joint stereo 3d object detection and implicit surface reconstruction"
- Select a language for the TTS:
- UK English Female
- UK English Male
- US English Female
- US English Male
- Australian Female
- Australian Male
- Language selected: (auto detect) - EN
Play all audios:
ABSTRACT We present a new learning-based framework S-3D-RCNN that can recover accurate object orientation in SO(3) and simultaneously predict implicit rigid shapes from stereo RGB images.
For orientation estimation, in contrast to previous studies that map local appearance to observation angles, we propose a progressive approach by extracting meaningful Intermediate
Geometrical Representations (IGRs). This approach features a deep model that transforms perceived intensities from one or two views to object part coordinates to achieve direct egocentric
object orientation estimation in the camera coordinate system. To further achieve finer description inside 3D bounding boxes, we investigate the implicit shape estimation problem from stereo
images. We model visible object surfaces by designing a point-based representation, augmenting IGRs to explicitly address the unseen surface hallucination problem. Extensive experiments
validate the effectiveness of the proposed IGRs, and S-3D-RCNN achieves superior 3D scene understanding performance. We also designed new metrics on the KITTI benchmark for our evaluation of
implicit shape estimation. SIMILAR CONTENT BEING VIEWED BY OTHERS ENHANCED MULTI VIEW 3D RECONSTRUCTION WITH IMPROVED MVSNET Article Open access 19 June 2024 DENSE MONOCULAR DEPTH
ESTIMATION FOR STEREOSCOPIC VISION BASED ON PYRAMID TRANSFORMER AND MULTI-SCALE FEATURE FUSION Article Open access 25 March 2024 A SIMPLE MONOCULAR DEPTH ESTIMATION NETWORK FOR BALANCING
COMPLEXITY AND ACCURACY Article Open access 15 April 2025 INTRODUCTION > _“The usefulness of a representation depends upon how well suited > it is to the purpose for which it is
used”._ –Marr1 Estimating 3D attributes of outdoor objects is a fundamental vision task enabling many important applications. For example, in vision-based autonomous driving and traffic
surveillance systems2, accurate vehicle orientation estimation (VOE) can imply a driver’s intent of travel direction, assist motion prediction and planning, and help identify anomalous
behaviors. In outdoor augmented reality systems, rigid shape estimation can enable photo-realistic lighting and physics-based surface effect simulation. In auto-labeling applications3,
off-board deep 3D attribute estimation models serve as an important component in a data closed-loop platform by speeding up the labeling efficiency. This study proposes a new multi-task
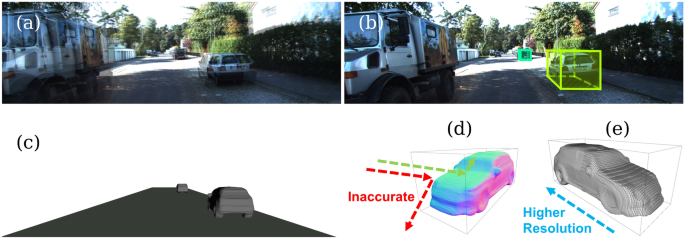
model to fulfill this task, which takes a pair of calibrated images (Fig. 1a) and can detect objects as bounding boxes (Fig. 1b) as well as estimate their implicit shapes (Fig. 1c). Even
though the binocular human visual system can recover _multiple_ 3D object properties effortlessly from a glance, this task is challenging for computers to accomplish. The difficulty results
from a lack of geometry information after image formation, which causes the _semantic gap_ between RGB pixels and unknown 3D properties. This problem is even exacerbated by a huge variation
in object appearances. Recently, advances in deep learning greatly facilitated the representation learning process from data, where a neural network predicts 3D attributes from images4,5. In
this paradigm, paired images and 3D annotations are specified as inputs and learning targets respectively for supervising a deep model. No intermediate representation is designed in these
studies, which need a large number of training pairs to approximate the highly non-linear mapping from the pixel space to 3D geometrical quantities. To address this problem, instead of
directly regressing them from pixels with a black-box neural network, we propose a progressive mapping from pixels to 3D attributes. This design is inspired by Marr’s representational
framework of vision1. In Marr’s framework, intermediate representations, i.e., the \(2\frac{1}{2}\)-D sketch, are computed from low-level pixels and are later lifted to 3D model
representations. However, how to design effective intermediate representations toward accurate and robust outdoor 3D attribute recovery is still task-dependent and under-explored. In this
study, our research question is _can a neural network extract explicit geometrical quantities from monocular/stereo RGB images and use them for effective object pose/shape estimation?_ The
conference version of this study6 addressed a part of the question, i.e., how to estimate orientation for one class of objects (vehicles) from a single RGB image. The proposed model,
Ego-Net, computed part-based screen coordinates from object part heatmaps and further lifted them to 3D object part coordinates for accurate orientation inference. While the study6 is
effective for VOE, it is limited in several aspects which demands further exploration. Firstly, the approach was demonstrated only for a single-view setting. The difficulty of monocular
depth estimation makes it less competent in perception accuracy compared with multi-view systems. Thus, an extension to multi-view sensor configuration and a study of the effectiveness of
the proposed IGRs in such cases is highly favorable and complementary. Secondly, the approach was only validated for vehicles and not shown for other common articulated objects such as
pedestrians. These objects are smaller and have much fewer training labels in the used dataset. It would be intriguing whether the proposed IGRs show consistent effectiveness or not. Lastly,
the approach can only predict object orientation. It does not unlock the full potential of the extracted high-resolution instance features to recover a more detailed rigid shape
description, and neither does it discuss how to design effective IGRs to achieve it. A complete and detailed rigid shape description beyond 3D bounding boxes is desirable for various machine
vision applications. For example, an autonomous perception system can give a more accurate collision prediction _within_ an object’s 3D bounding box. As an illustration, the green ray
reflecting on the predicted object surface in Fig. 1d cannot be obtained by using 3D bounding boxes to represent objects due to the lack of fine-grained surface normal. In addition, our
approach describes rigid objects with implicit representations, which can be rendered with varying resolutions (Fig. 1e). To fully address our research question, this study presents an
extended model S-3D-RCNN for joint object detection, orientation estimation, and implicit shape estimation from a pair of RGB images. Firstly, we demonstrate the effectiveness of the
proposed IGRs in a stereo perception setting, where part-based screen coordinates aggregated from two views further improve the VOE accuracy. Secondly, we validate the robustness of the
proposed IGRs for other outdoor objects such as pedestrians. These tiny objects are underrepresented in the training dataset, yet the proposed approach still achieves accurate orientation
estimation. Lastly, we propose several new representations in the framework to further extend EgoNet for implicit shape estimation. We formulate the problem of implicit shape estimation as
an unseen surface hallucination problem and propose to address it with a point-based visible surface representation. For quantitative evaluation, we further propose two new metrics to extend
KITTI’s object detection evaluation7 to consider the retrieval of the object surface. In summary, this study extends the previous conference version in various aspects with the following
added contributions. * It explores the proposed IGRs in a stereo-perception setting and validates the effectiveness of the proposed approach in recovering orientation in SO(3) for two-view
inputs. * It shows the proposed approach is not limited to rigid objects and has strong orientation estimation performance for other small objects that may have fewer training labels. * It
extends the representational framework in Ego-Net with several new IGRs to achieve implicit shape estimation from stereo region-of-interests. To the best of our knowledge, Ego-Net++ is the
first stereo image-based approach for 3D object detection and implicit rigid shape estimation. * To quantitatively evaluate the proposed implicit shape estimation task, two new metrics are
designed to extend the previous average precision metrics to consider the object surface description. We introduce and compare with relevant studies in the next section and revisit Ego-Net
in section “System-level comparison with previous studies”. We then detail extended studies in designing Ego-Net++ in section “Module-level comparison with previous studies” followed by
experimental evaluations in section “Conclusion”. RELATED WORK This study features outdoor environment, orientation estimation, and implicit shape reconstruction. It draws connections with
prior studies in the following domains yet has unique contributions. IMAGE-BASED 3D SCENE UNDERSTANDING requires recovering 3D object properties from RGB images which usually consist of
_multiple_ sub-tasks8,9,10,11,12,13,14,15. Two popular paradigms were proposed. The _generative_, a.k.a _analysis-by-synthesis_ approaches16,17,18,19 build generative models of image
observation and unknown 3D attributes. During inference, they search in the 3D state space to find an optimum that best explains the image evidence. However, good initialization and
iterative optimization are required to search in a high-dimensional state space. In contrast, the _discriminative_ approaches20,21,22,23 directly learn a mapping from image observation to 3D
representations. Our approach can be categorized into the latter yet is unique. Unlike previous studies that are only applicable for indoor environments with small depth
variation11,24,25,26,27,28 or only consider the monocular camera setting22,29,30,31, our framework can exploit two-view geometry to accurately locate objects as well as enables
resolution-agnostic implicit shape estimation in challenging outdoor environments. Compared with recent multi-view reconstruction studies32,33, our study does not take 3D mesh inputs as32 or
use synthetic image inputs as33. LEARNING-BASED 3D OBJECT DETECTION learns a function that maps sensor input to objects represented as 3D bounding boxes34. Depending on the sensor
configuration, previous studies can be categorized into RGB-based methods5,6,35,36,37,38,39 and LiDAR-based approaches40,41,42,43. Our approach is RGB-based which does not require expensive
range sensors. While previous RGB-based methods can describe objects up to a 3D bounding box representation, the quality of shape predictions within the bounding boxes was not evaluated with
existing metrics. Our extended study fills this gap by proposing new metrics and designing an extended model that complements Ego-Net with implicit shape reconstruction capability from
stereo inputs. LEARNING-BASED ORIENTATION ESTIMATION FOR 3D OBJECT DETECTION seeks a function that maps pixels to instance orientation in the camera coordinate system via learning from data.
Early studies44,45 utilized hand-crafted features46 and boosted trees for discrete pose classification (DPC). More recent studies replace the feature extraction stage with deep models.
ANN47 and DAVE48,49 classify instance feature maps extracted by CNN into discrete bins. To deal with images containing multiple instances, Fast-RCNN-like architectures were employed
in34,50,51,52,53 where region-of-interest (ROI) features were used to represent instance appearance and a classification head gives pose prediction. Deep3DBox4 proposed _MultiBin_ loss for
joint pose classification and residual regression. Wasserstein loss was promoted in54 for DPC. Our Ego-Net6 is also a learning-based approach but possesses key differences. Our approach
promotes learning explicit part-based IGRs while previous works do not. With IGRs, Ego-Net is robust to occlusion and can directly estimate global (egocentric) pose in the camera coordinate
system while previous works can only estimate relative (allocentric) pose. Compared to Ego-Net, orientation estimation with Ego-Net++ in this extended study is no longer limited to monocular
inputs and rigid objects. In addition, Ego-Net++ can further achieve object surface retrieval for rigid objects while Ego-Net cannot. INSTANCE-LEVEL MODELING IN 3D OBJECT DETECTION builds a
feature representation for a single object to estimate its 3D attributes22,53,55,56,57. FQ-Net55 draws a re-projected 3D cuboid on an instance patch to predict its 3D Intersection over
Union (IoU) with the ground truth. RAR-Net57 formulates a reinforcement learning framework for instance location prediction. 3D-RCNN22 and GSNet53 learn a mapping from instance features to
the PCA-based shape codes. Ego-Net++ in this study is a new instance-level model in that it can predict the implicit shape and can utilize stereo imagery while previous studies cannot.
NEURAL IMPLICIT SHAPE REPRESENTATION was proposed to encode object shapes as latent vectors via a neural network58,59,60,61,62, which shows an advantage over classical shape representations.
However, many prior works focus on using perfect synthetic point clouds as inputs and few have explored its inference in 3D object detection (3DOD) scenarios. Instead, we address inferring
such representations under a realistic object detection scenario with stereo sensors by extending the IGRs in Ego-Net to accomplish this task. METHOD OVERALL FRAMEWORK Our framework
S-3D-RCNN detects objects and estimates their 3D attributes from a pair of stereo images with designed intermediate representations. S-3D-RCNN consists of a proposal model \({\mathscr {D}}\)
and an instance-level model \({\mathscr {E}}\) (Ego-Net++) for instance-level 3D attribute recovery as shown in Fig. 2. \({\mathscr {E}}\) is agnostic to the design choice of \({\mathscr
{D}}\) and can be used as a plug-and-play module. Given an image pair \(({\mathscr {L}}, {\mathscr {R}})\) captured by stereo cameras with left camera intrinsics \(\text {K}_{3 \times 3}\),
\({\mathscr {D}}\) predicts _N_ cuboid proposals \(\{ b_i \}_{i=1}^{N}\) as \({\mathscr {D}}({\mathscr {L}}, {\mathscr {R}}; \theta _{{\mathscr {D}}}) = \{ b_q \}_{q=1.}^{N}\) Conditioned on
each proposal \(b_i\), \({\mathscr {E}}\) constructs instance-level representations and predicts its orientation as\( {\mathscr {E}}({\mathscr {L}}, {\mathscr {R}}; \theta _{{\mathscr
{E}}}|b_i) = \varvec{\theta }_{i.}\) In addition, for rigid object proposals (i.e., vehicles in this study), \({\mathscr {E}}\) can further predict its implicit shape representation. In
implementation, \({\mathscr {D}}\) is designed as a voxel-based 3D object detector as shown in Fig. 3. The following sub-sections first revisit the motivation and representation design in
Ego-Net, and then highlight which new representations are introduced in Ego-Net++ for a stronger 3D scene understanding performance. EGO-NET: MONOCULAR EGOCENTRIC VEHICLE POSE ESTIMATION
WITH IGRS ORIENTATION ESTIMATION WITH A PROGRESSIVE MAPPING Previous studies4,5,22,64 regress vehicle orientation with the computational graph in Eq. (1). A CNN-based model \({\mathscr
{N}}\) is used to map local instance appearance \({\textbf{x}}_i\) to allocentric pose, i.e., 3D orientation in the object coordinate system (OCS), which is then converted to the egocentric
pose, i.e., orientation in the camera coordinate system (CCS). The difference between these two coordinate systems is shown in Fig. 4. This two-step design is a workaround since an object
with the same egocentric pose \(\varvec{\theta }_i\) can produce different local appearance depending on its location22 and learning the mapping from \({\textbf{x}}_i\) to \(\varvec{\theta
}_i\) is ill-posed. In this two-step design, OCS was estimated by another module. The error of this module can propagate to the final estimation of egocentric poses, and optimizing
\({\mathscr {N}}\) does not optimize the final target directly. Another problem of this design is that the mapping from pixels \({\textbf{x}}_i\) to pose vectors \(\varvec{\alpha }_i\) is
highly non-linear and difficult to approximate65. $$\begin{aligned} \begin{array}{llll} {\textbf{x}}_i &{} \xrightarrow {{\mathscr {N}}} &{} ~~ \varvec{\alpha }_i &{}
\xrightarrow {convert} ~~ \varvec{\theta }_i \\ &{} &{} \text {OCS} &{} \nearrow {}\\ \end{array} \end{aligned}$$ (1) Ego-Net instead learns a mapping from images to egocentric
poses to optimize the target directly. However, instead of relying on a black box model to fit such a non-linear mapping, it promotes a progressive mapping, where coordinate-based IGRs are
extracted from pixels and eventually lifted to the 3D target. Specifically, Ego-Net is a composite function with learnable modules \(\{{\mathscr {H}},{\mathscr {C}}, Li\}\). Given the
cropped 2D image patch of one proposal \({\textbf{x}}_i\), Ego-Net predicts its egocentric pose as \({\mathscr {E}}({\textbf{x}}_i) = Li({\mathscr {A}}_i({\mathscr {C}}({\mathscr
{H}}({\textbf{x}}_i)))) = \varvec{\theta }_i\). Figure 5 depicts Ego-Net, whose computational graph is shown in Eq. (2). \({\mathscr {H}}\) extracts heatmaps \(h({\textbf{x}}_i)\) for 2D
object parts that are mapped by \({\mathscr {C}}\) to coordinates \(\phi _l({\textbf{x}}_i)\) representing their local location on the patch. \(\phi _l({\textbf{x}}_i)\) is converted to the
global image plane coordinates \(\phi _g({\textbf{x}}_i)\) with an affine transformation \({\mathscr {A}}_i\) parametrized with scaling and 2D translation. \(\phi _g({\textbf{x}}_i)\) is
further lifted to a 3D representation \(\psi ({\textbf{x}}_i)\) by _Li_. The final pose prediction derives from \(\psi ({\textbf{x}}_i)\). $$\begin{aligned} \begin{array}{lllllllllll}
{\textbf{x}}_i&\xrightarrow {{\mathscr {H}}}&h({\textbf{x}}_i)&\xrightarrow {{\mathscr {C}}}&\phi _l({\textbf{x}}_i)&\xrightarrow {{\mathscr {A}}_i}&\phi
_g({\textbf{x}}_i)&\xrightarrow {Li}&\psi ({\textbf{x}}_i)\rightarrow & {} \varvec{\theta }_i \end{array} \end{aligned}$$ (2) DESIGN OF LABOR-FREE INTERMEDIATE REPRESENTATIONS
The IGRs in Eq. (2) are designed based on the following considerations: _Availability_: It is favorable if the IGRs can be easily derived from existing ground truth annotations with none or
minimum extra manual effort. Thus we define object parts from existing 3D bounding box annotations. _Discriminative_: The IGRs should be indicative for orientation estimation, so that they
can serve as a good bridge between visual appearance input and the geometrical target. _Transparency_: The IGRs should be easy to understand, which makes them debugging-friendly and
trustworthy for applications such as autonomous driving. Thus IGRs are defined with explicit meaning in Ego-Net. With the above considerations, we define the 3D representation \(\psi
({\textbf{x}}_i)\) as a sparse 3D point cloud (PC) representing an interpolated cuboid. Autonomous driving datasets such as KITTI7 usually label instance 3D bounding boxes from captured
point clouds where an instance \({\textbf{x}}_i\) is associated with its centroid location in the camera coordinate system \({\textbf{t}}_i = [t_x, t_y, t_z]\), size \([h_i, w_i, l_i]\), and
its egocentric pose \(\varvec{\theta }_i\). For consistency, many prior studies only use the yaw angle denoted as \(\theta _i\). As shown in Fig. 6, denote the 12 lines comprising a 3D
bounding box as \(\{{\textbf{l}}_j\}_{j=1}^{12}\), where each line is represented by two endpoints (Start and End) as \({\textbf{l}}_j = [{\textbf{p}}_j^{s}; {\textbf{p}}_j^{e}]\).
\({\textbf{p}}_j^v\) (_v_ is _s_ or _e_) is a 3-vector \((X_j^{v}, Y_j^{v}, Z_j^{v})\) representing the point’s location in the camera coordinate system. As a complexity-controlling
parameter, _q_ more points are sampled from each line with a pre-defined interpolation matrix \(B_{q \times 2}\) as $$\begin{aligned} \begin{bmatrix} {\textbf{p}}_j^1 \\ {\textbf{p}}_j^2 \\
\dots \\ {\textbf{p}}_j^q \\ \end{bmatrix} = B_{q \times 2} \begin{bmatrix} {\textbf{p}}_j^{s} \\ {\textbf{p}}_j^{e} \\ \end{bmatrix} = \begin{bmatrix} \beta _1 &{} 1 - \beta _1 \\ \beta
_2 &{} 1 - \beta _2 \\ \dots &{} \dots \\ \beta _q &{} 1 - \beta _q \\ \end{bmatrix} \begin{bmatrix} {\textbf{p}}_j^{s} \\ {\textbf{p}}_j^{e} \\ \end{bmatrix}. \end{aligned}$$
(3) The 8 endpoints, the instance’s centroid, and the interpolated points for each of the 12 lines form a set of \(9 + 12q\) points. The concatenation of these points forms a \(9 + 12q \) by
3 matrix \(\tau ({\textbf{x}}_i)\). Since we do not need the 3D target \(\psi ({\textbf{x}}_i)\) to encode location, we deduct the instance translation \({\textbf{t}}_i\) from \(\tau
({\textbf{x}}_i)\) and represent \(\psi ({\textbf{x}}_i)\) as a set of \(8 + 12q\) points representing the shape relative to the centroid \(\psi ({\textbf{x}}_i) = \left\{ \left( X_{j}^{v} -
t_x, Y_{j}^{v} - t_y, Z_{j}^{v} - t_z \right) \right\} \) where \(v\in \{s,1,\ldots ,q,e\}\) and \(j\in \{1,2,\ldots ,12\}\). Larger _q_ provides more cues for inferring pose yet increases
complexity. In practice, we choose \(q=2\) and the right figure of Fig. 6 shows an example with \(B_{2 \times 2}= \begin{bmatrix} \frac{3}{4} &{} \frac{1}{4} \\ \frac{1}{4} &{}
\frac{3}{4} \\ \end{bmatrix}\)and 2 points are interpolated for each line. Serving as the 2D representation to be located by \({\mathscr {H}}\) and \({\mathscr {C}}\), \(\phi
_g({\textbf{x}}_i)\) is defined to be the projected _screen coordinates_ of \(\tau ({\textbf{x}}_i)\) given camera intrinsics \(\text {K}_{3 \times 3}\) as $$\begin{aligned} \phi
_g({\textbf{x}}_i) = \text {K}_{3 \times 3} \tau ({\textbf{x}}_i). \end{aligned}$$ (4) \(\phi _g({\textbf{x}}_i)\) implicitly encodes instance location on the image plane so that it is less
ill-posed to estimate egocentric pose from it directly. In summary, these IGRs can be computed with zero extra manual annotation, are easy to understand, and contain rich information for
estimating the instance orientation. EGO-NET++: TOWARDS MULTI-VIEW PERCEPTION AND IMPLICIT SHAPE INFERENCE To study the effectiveness of _screen coordinates_ in encoding two-view
information, and achieve a finer description for perceived objects, several new IGRs are designed in Ego-Net++. ORIENTATION ESTIMATION WITH PAIRED PART COORDINATES Under the stereo
perception setting, another viewpoint provides more information to infer the unknown object orientation. It is thus necessary to extend the IGRs to aggregate information from both views. In
Ego-Net++, _paired part coordinates_ (PPCs) are defined with a simple yet effective concatenation operation to aggregate two-view information as a k by 4 representation $$\begin{aligned}
\phi _g \left( {\textbf{x}}_i^{{\mathscr {L}}}, {\textbf{x}}_i^{{\mathscr {R}}}\right) = \phi _g \left( {\textbf{x}}_i^{{\mathscr {L}}}\right) \oplus \phi _g \left( {\textbf{x}}_i^{{\mathscr
{R}}}\right) , \end{aligned}$$ (5) PPC enhances the IGR in Ego-Net with disparity, i.e., differences of part coordinates in two views. Such disparity provides geometrical cues for object
part depth and have larger mutual information with the target orientation. PPC is illustrated in Fig. 7. for one object part, and it extends the computational graph in Eq. (2) as
$$\begin{aligned} \begin{array}{lllllllllllll} {\textbf{x}}_i^{{\mathscr {L}}} &{} \xrightarrow {{\mathscr {H}}} &{} h \left( {\textbf{x}}_i^{{\mathscr {L}}}\right) &{}
\xrightarrow {{\mathscr {C}}} &{} \phi _l \left( {\textbf{x}}_i^{{\mathscr {L}}}\right) &{} \xrightarrow {{\mathscr {A}}_i^{{\mathscr {L}}}} &{} \phi _g \left(
{\textbf{x}}_i^{{\mathscr {L}}}\right) &{} \xrightarrow {\oplus } &{} \phi _g \left( {\textbf{x}}_i^{{\mathscr {L}}}, {\textbf{x}}_i^{{\mathscr {R}}}\right) &{} \xrightarrow {Li}
&{} \psi ({\textbf{x}}_i) &{} \rightarrow &{} \varvec{\theta }_i \\ {\textbf{x}}_i^{{\mathscr {R}}} &{} \xrightarrow {{\mathscr {H}}} &{} h \left(
{\textbf{x}}_i^{{\mathscr {R}}}\right) &{} \xrightarrow {{\mathscr {C}}} &{} \phi _l \left( {\textbf{x}}_i^{{\mathscr {R}}}\right) &{} \xrightarrow {{\mathscr {A}}_i^{{\mathscr
{R}}}} &{} \phi _g \left( {\textbf{x}}_i^{{\mathscr {R}}}\right) &{} \nearrow &{} &{} &{} &{} &{} \end{array} \end{aligned}$$ (6) The learnable modules are
implemented with convolutional and fully-connected layers, and a diagram of orientation estimation from stereo images is shown in Fig. 8. During training, ground truth IGRs are available to
penalize the predicted heatmaps, predicted 2D coordinates, and 3D coordinates. Such supervision is implemented with \(L_2\) loss for heatmaps and \(L_1\) loss for coordinates. In inference,
the predicted egocentric pose is computed from the predicted 3D coordinates \(\psi ({\textbf{x}}_i)\). Denote the 3D coordinates at a canonical pose as \(\psi ^{0}({\textbf{x}}_i)\), the
predicted pose is obtained by estimating a rotation \(R(\varvec{\theta }_i)\) from \(\psi ^{0}({\textbf{x}}_i)\) to \(\psi ({\textbf{x}}_i)\). $$\begin{aligned} \varvec{\theta }_i =\arg \min
_{\varvec{\theta }_i}\left| \left| R(\varvec{\theta }_i)\psi ^{0}({\textbf{x}}_i) - \psi ({\textbf{x}}_i)\right| \right| , \end{aligned}$$ (7) In implementation, this least-square problem
is solved with singular value decomposition (SVD). This process is efficient due to a small number of parts. IMPLICIT SHAPE ESTIMATION VIA SURFACE HALLUCINATION Previous sub-sections enable
recovering object orientation from one or two views. However, such perception capability is limited to describing objects as 3D bounding boxes, failing at a more detailed representation
within the box. While some previous studies53,66,67,68 explore shape estimation for outdoor rigid objects, they cannot exploit the stereo inputs or require PCA-based templates53,66,67,68
which are limited to a fixed mesh topology53. In contrast, Ego-Net++ can take advantage of stereo information and conduct implicit shape estimation which can produce flexible
resolution-agnostic meshes. To the best of our knowledge, how to design effective intermediate representations for recovering implicit rigid shapes for outdoor objects with stereo cameras is
under-explored. We design the IGRs for implicit shape estimation based on the following fact. The implicit shape representation \(s({\textbf{x}}_i)\) for each rigid object describes its
complete surface geometry. However, the observation from stereo cameras only encodes a portion of the object’s surface. This indicates that the implicit shape reconstruction problem can be
modeled as an _unseen surface hallucination_ problem, i.e., one needs to infer the unseen surface based on partial visual evidence. Specifically, Ego-Net++ addresses this problem by
extending the IGRs in Ego-Net with several new representations and learning a progressive mapping from stereo appearances to \(s({\textbf{x}}_i)\). This mapping is represented as a composite
function \(E \circ Ha \circ O \circ V, \) that has learnable parameters \(\{Ha, V, E\}\) and the following computational graph $$\begin{aligned} \begin{array}{lllllllll}
{\textbf{x}}_i^{{\mathscr {L}}}, {\textbf{x}}_i^{{\mathscr {R}}}&\xrightarrow {V}&v({\textbf{x}}_i)&\xrightarrow {O}&o({\textbf{x}}_i)&\xrightarrow
{Ha}&c({\textbf{x}}_i)&\xrightarrow {E}&s({\textbf{x}}_i). \end{array} \end{aligned}$$ (8) Here \(v({\textbf{x}}_i)\) represents the visible object surface. After a normalization
operator _O_, such representation is converted to the OCS. To recover the missing surface, a point-based encoder-decoder _Ha_ hallucinates a complete surface based on learned prior
knowledge. _E_ encodes the complete shape into an implicit shape vector. THE VISIBLE-SURFACE REPRESENTATION We propose a point-based representation for the visible object surface. Given a
pair of stereo RoIs, _V_ estimates the foreground mask and depth, samples a set of pixels from the foreground, and re-projects them to the CCS. Denote \({\mathscr {M}}({\textbf{x}}_i)\) as
the predicted set of foreground pixels, we sample _e_ elements from it as \({\mathscr {M}}^{sp}({\textbf{x}}_i)\). These elements are re-projected to the CCS to form a set of _e_ 3D points
as $$\begin{aligned} \{\text {K}_{3 \times 3}^{-1} \begin{bmatrix} m_z*m^x \\ m_z*m^y \\ m_z \\ \end{bmatrix}\vert m \in {\mathscr {M}}^{sp}({\textbf{x}}_i)\subset {\mathscr
{M}}({\textbf{x}}_i)\}, \end{aligned}$$ (9) where \((m^x, m^y)\) denotes the screen coordinates of pixel _m_. Concatenating these elements gives a 3 by _e_ matrix \(v({\textbf{x}}_i)\)
encoding the visible instance PC in the CCS. In implementation, \({\mathscr {M}}({\textbf{x}}_i)\) is obtained by applying fully convolutional layers using 2D features for foreground
classification. To obtain the depth prediction for the foreground region, a local cost volume is constructed to estimate disparity for the local patch. The disparities are then converted to
depth as \(m^z = fB/m^{disp}\) where \(m^{disp}\), _B_, and _f_ are the estimated disparity, stereo baseline length, and focal length respectively. HALLUCINATION WITH NORMALIZED COORDINATES
We found the learning of unseen surface hallucination more difficult when the input point coordinates represent a large variation of object pose and size. Thus we propose to disentangle the
estimation of rigid shape from object pose. Specifically, we use operator _O_ to normalize the visible object surface to a canonical OCS with a similarity transformation. Denote a detected
object \(b_i\) as a 7-tuple \(b_i = (x_i, y_i, z_i, h_i, w_i, l_i, \theta _i)\), where \((x_i, y_i, z_i)\), \((h_i, w_i, l_i)\) and \(\theta _i\) denote its translation, size (height, width,
length) and orientation in the CCS respectively. The normalized coordinates are computed conditioned on \(b_i\) as $$\begin{aligned} o({\textbf{x}}_i)= \begin{gathered} \begin{bmatrix}
cos\theta _i*l_i &{} 0 &{} sin\theta _i*l_i &{} t_x \\ 0 &{} l_i&{} 0&{} t_y \\ -sin\theta _i*l_i &{} 0&{} cos\theta _i*l_i&{} t_z \\ 0 &{} 0&{}
0&{} 1 \end{bmatrix} ^{-1} \begin{bmatrix} \big \vert \\ v({\textbf{x}}_i)\\ \big \vert \\ {{\textbf {1}}} \end{bmatrix}. \end{gathered} \end{aligned}$$ (10) _Ha_ is implemented as a
point-based encoder-decoder module, which extracts point-level features69 from \(o({\textbf{x}}_i)\) and infers \(N_c\) by 3 coordinates \(c({\textbf{x}}_i)\) to represent the complete
surface. Finally, the shape encoder _E_ maps the estimated complete surface \(c({\textbf{x}}_i)\) into a latent vector \(s({\textbf{x}}_i)\) that encodes the object’s implicit shape. To
extract a mesh representation from the predicted implicit shape code, \({\mathscr {E}}\) uses the occupancy decoder59 where a set of grid locations is specified and predicts the occupancy
field on such grid. Note this grid is not necessarily evenly distributed thus one can easily use the shape code in a resolution-agnostic manner. Given the occupancy field, we then use the
Marching Cube algorithm70 to extract an isosurface as a mesh representation. To optimize the learnable parameters during training, the supervision consists of the cross-entropy segmentation
loss, the smooth \(L_1\) disparity estimation loss, and the hallucination loss implemented as Chamfer distance. We train the shape decoder on ShapeNet71 by randomly sampling grid locations
within object 3D bounding boxes with paired ground truth occupancy. In inference, we apply zero padding if \(Card({\mathscr {M}}({\textbf{x}}_i))<e\). PENALIZING IN-BOX DESCRIPTIONS FOR
3DOD Per the new IGRs introduced in Ego-Net++, S-3D-RCNN can estimate 3D bounding boxes accurately from stereo cameras as well as describe a finer rigid shape _within_ the bounding boxes.
However, existing 3DOD studies on KITTI7 cannot measure the goodness of a more detailed shape beyond a 3D bounding box representation. To fill this gap and validate the effectiveness of the
new IGRs, we contribute new metrics to KITTI for the intended evaluation. As a reference metric, the official _Average Orientation Similarity_ (_AOS_) metric in KITTI is defined as
$$\begin{aligned} AOS = \frac{1}{11}\sum _{r\in \{0, 0.1, \ldots , 1\}}\text {max}_{{\tilde{r}}:{\tilde{r}}\ge r}s({\tilde{r}}), \end{aligned}$$ (11) where _r_ is the detection recall and
\(s(r) \in [0, 1]\) is the orientation similarity (OS) at recall level _r_. OS is defined as $$\begin{aligned} s(r) = \frac{1}{|D(r)|}\sum _{b_i \in D(r)}\frac{1 + \text {cos}\Delta
_{i}^{\theta }}{2}\delta _{i} \end{aligned}$$ (12) , where _D_(_r_) denotes the set of all object predictions at recall rate _r_ and \(\Delta ^{\theta }_{i}\) is the difference in yaw angle
between estimated and ground-truth orientation for object _i_. If \(b_i\) is a 2D false positive, i.e., its 2D intersection-over-union (IoU) with ground truth is smaller than a threshold
(0.5 or 0.7), \(\delta _i = 0\). Note that _AOS_ itself builds on the official average precision metric \(AP_{2D}\) and is upper-bounded by \(AP_{2D}\). \(AOS = \text {1}\) if both the
object detection and the orientation estimations are perfect. Based on _Minimal Matching Distance_ (MMD)72,73, we propose a new metric \(AP_{MMD}\) in the same manner as $$\begin{aligned}
AP_{MMD} = \frac{1}{11}\sum _{r\in \{0, 0.1, \ldots , 1\}}\text {max}_{{\tilde{r}}:{\tilde{r}}\ge r}s_{MMD}({\tilde{r}}) \end{aligned}$$ (13) where _r_ is the same detection recall and
\(s_{MMD}(r) \in [0, 1]\) is the MMD similarity (MMDS) at recall level _r_. MMDS is defined as $$\begin{aligned} s_{MMD}(r) = \frac{1}{|D(r)|}\sum _{b_i \in D(r)}\left[ (\gamma -
MMD(c({\textbf{x}}_i)) * \frac{1}{\gamma }\right] \delta _i^{MMD}, \end{aligned}$$ (14) where \(\delta _i^{MMD}\) is a indicator and \(MMD(c({\textbf{x}}_i))\) denotes the MMD of prediction
_i_ which measures the quality of the predicted surface. If the _i_-th prediction is a false postive or \(MMD(c({\textbf{x}}_i)) > \gamma \), \(\delta _i^{MMD} = 0\). \(AP_{MMD}\) is thus
also upper-bounded by the official \(AP_{2D}\). \(AP_{MMD} = AP_{2D}\) if and only if \(MMD(c({\textbf{x}}_i)) = 0\) for all predictions. In experiments we set \(\gamma \) as 0.05. Since
instance-level ground truth shape is not available in KITTI, \(MMD(c({\textbf{x}}_i))\) is implemented as category-level similarity similar to72,73. For a predicted instance PC
\(c({\textbf{x}}_i)\), it is defined as the minimal \(L_2\) Chamfer distance between it and a collection of template PCs in ShapeNet71 that has the same class label. It is formally expressed
as \(MMD(c({\textbf{x}}_i)) = \min _{{\mathscr {G}} \in SN} d_{CD}(c({\textbf{x}}_i), {\mathscr {G}}),\) where _SN_ stands for the set of ShapeNet template PCs and
\(d_{CD}(c({\textbf{x}}_i), {\mathscr {G}})\) is defined as $$\begin{aligned} d_{CD}(c({\textbf{x}}_i), {\mathscr {G}}) = \frac{1}{|c({\textbf{x}}_i)|}\sum _{p\in c({\textbf{x}}_i)}\min _{g
\in {\mathscr {G}}}||p - g|| + \frac{1}{|{\mathscr {G}}|}\sum _{g\in {\mathscr {G}}}\min _{p \in c({\textbf{x}}_i)}||g - p||. \end{aligned}$$ (15) During the evaluation, we downloaded 250
ground truth car PCs that were used in72,73 for consistency. The evaluation of \(AP_{MMD}\) considers false negatives. For completeness, we also design _True Positive Minimal Matching
Distance_ (MMDTP) to evaluate MMD for the true positive predictions similar to74. We define MMDTP@\(\beta \) as the average MMD of the predicted objects that have 3D IoU > \(\beta \) with
at least one ground truth object, $$\begin{aligned} MMDTP@\beta = \frac{1}{\sum _{i=1}^{N}TP(i)}\sum _{i=1}^{N}TP(i)*MMD(c({\textbf{x}}_i)), \end{aligned}$$ (16) where _TP_(_i_) is 1 if
\(b_i\) is a true positive and 0 otherwise as $$\begin{aligned} TP(i) = {\left\{ \begin{array}{ll} 1, &{}\text{ if } IoU_{3D}(b_i, gt) > \beta , \exists gt\\ 0, &{} \text{ else }.
\end{array}\right. } \end{aligned}$$ EXPERIMENTS We first introduce the used benchmark dataset and the evaluation metrics, followed by a system-level comparison between our S-3D-RCNN with
other approaches in terms of outdoor 3D scene understanding capabilities. We further present a module-level comparison to demonstrate the effectiveness of Ego-Net++. Finally, we conduct an
ablation study on key design factors and hyper-parameters in EgoNet++. For more training and implementation details, please refer to our supplementary material. EXPERIMENTAL SETTINGS DATASET
AND EVALUATION METRICS. We employ the KITTI object detection benchmark7 that contains stereo RGB images captured in outdoor scenes. The dataset is split into 7481 training images and 7518
testing images. The training images are further split into the _train_ split and the _val_ split containing 3712 and 3769 images respectively. For consistency with prior studies, we use the
_train_ split for training and report results on the _val_ split and the testing images. We use the official average precision metrics as well as our newly designed \(AP_{MMD}\) and MMDTP.
As defined in Eq. (11) in the main text, _AOS_ is used to assess the system performance for joint object detection and orientation estimation. _3D Average Precision_ (\(AP_{3D}\)) measures
precisions at the same recall values where a true positive prediction has 3D IoU > 0.7 with the ground truth one. _BEV Average Precision_ (\(AP_{BEV}\)) instead uses 2D IoU > 0.7 as
the criterion for true positives where the 3D bounding boxes are projected to the ground plane. Each ground truth label is assigned a difficulty level (easy, moderate, or hard) depending on
its 2D bounding box height, occlusion level, and truncation level. SYSTEM-LEVEL COMPARISON WITH PREVIOUS STUDIES Ego-Net++ can be combined with a 2D proposal model to build a strong system
for object orientation/rigid shape recovery. JOINT OBJECT DETECTION AND ORIENTATION ESTIMATION PERFORMANCE Ego-Net can be used with a 2D vehicle detection model to form a joint vehicle
detection and orientation estimation system, whose performance is measured by _AOS_. Per the proposals used in6, Table 1 compares the _AOS_ of our system using Ego-Net with other approaches
on the KITTI test set for the car category. Among the single-view image-based approaches, our system outperforms others by a clear margin. Our approach using a single image outperforms
Kinematic3D76 which exploits temporal information using RGB video. In addition to monocular orientation estimation, we show system performance with our \({\mathscr {E}}\) that can exploit
two-view information in Tables 1 and 2 for the car and pedestrian class respectively. Our S-3D-RCNN using \({\mathscr {E}}\) achieves improved vehicle orientation estimation performance. For
performance comparison of pedestrian orientation estimation, we use the same proposals in84. Using our \({\mathscr {E}}\) consistently outperforms the proposal model, and the system
performance based on RGB images even surpasses some LiDAR-based approaches42,83 that have more accurate depth measurements. This result indicates that the LiDAR point cloud is not
discriminative for determining the accurate orientation of distant non-rigid objects due to a lack of fine-grained visual information. In contrast, our image-based approach effectively
addresses the limitations of LiDAR sensors and can complement them in this scenario. COMPARISON OF 3D SCENE UNDERSTANDING CAPABILITY To our knowledge, S-3D-RCNN is the first model that
jointly performs accurate 3DOD and implicit rigid shape estimation for outdoor objects with stereo cameras. Table 3 presents a summary and comparison of perception capability with previous
image-based outdoor 3D scene understanding approaches. Qualitatively, S-3D-RCNN is the only method that can utilize stereo geometry as well as predict implicit shape representations.
Compared to the monocular method 3D-RCNN22 that uses template meshes with fixed topology, our framework can produce meshes in a resolution-agnostic way and can provide an accurate estimation
of object locations by exploiting two-view geometry. We show qualitative results in Fig. 9 where the predicted implicit shapes are decoded to meshes. Our approach shows accurate
localization performance along with plausible shape predictions, which opens up new opportunities for outdoor augmented reality. MODULE-LEVEL COMPARISON WITH PREVIOUS STUDIES Here we
demonstrate the effectiveness of EgoNet++ as a module. Based on the designed IGRs and progressive mappings in this study, we show how using Ego-Net++ can contribute to improved
orientation/shape estimation performance for state-of-the-art 3D scene understanding approaches. COMPARISON OF ORIENTATION ESTIMATION PERFORMANCE To assess if Ego-Net can help improve the
pose estimation accuracy of other 3DOD systems, we download proposals from other open-source implementations and use Ego-Net for orientation refinement. The result is summarized in Table 4
for the car category. While _AOS_ depends on the detection performance of these methods, using Ego-Net consistently improves the pose estimation accuracy of these approaches. This indicates
that Ego-Net is robust despite the performance of a vehicle detector varying with different recall levels. We also compare with OCM3D90 using the same proposals, and higher _AOS_ further
validates the effectiveness of our proposed IGRs for orientation estimation. For true positive predictions we plot the distribution of orientation estimation error versus different depth
ranges and occlusion levels in Fig. 10. The error in each bin is the averaged orientation estimation error for those instances that fall into it. While the performance of M3D-RPN5 and
D4LCN64 degrades significantly for distant and occluded cars, the errors of our approach increase gracefully. We believe that explicitly learning the object parts makes our model more robust
to occlusion as the visible parts can provide richer information for pose estimation. We visualize qualitative comparison with D4LCN64 in Fig. 11 in Bird’s eye view (BEV). The orientation
predictions are shown in BEV and the arrows point to the heading direction of those vehicles. From the local appearance, it can be hard to tell whether certain cars head towards or away from
the camera, as validated by the erroneous predictions of D4LCN64 since it regresses pose from local features. In comparison, our approach gives accurate egocentric pose predictions for
these instances and others that are partially occluded. Quantitative comparison with several 3D object detection systems on the KITTI _val_ split is shown in Table 5. Note that utilizing
Ego-Net can correct wrong pose predictions especially for difficult instances, which leads to improved 3D IoU and results in significantly improved \(AP_{BEV}\). Apart from using Ego-Net for
monocular detectors, we provide extended studies of using Ego-Net++ for a state-of-the-art stereo detector. Table 6 shows a comparison for the non-rigid pedestrian class where the same
proposals are used as88. Thanks to the effectiveness of PPC, our \({\mathscr {E}}\) significantly improves the 3DOD performance for these non-rigid objects and some examples are shown in
Fig. 12. This improvement shows the IGRs designed in this study are robust despite the training data for the pedestrian class being much fewer. COMPARISON OF SHAPE ESTIMATION PERFORMANCE
Here we present a quantitative comparison of rigid shape estimation quality using our new metric MMDTP. We compare with81 due to its availability of the official implementation. We
downloaded 13,575 predicted objects from its website in which 9,488 instances have 3D IoU large enough to compute [email protected] shown in Table 3. Our \({\mathscr {E}}\) can produce a complete
shape description of a detected instance thanks to our _visible surface representation_ and explicit modeling of the unseen surface hallucination problem. This leads to a significant
improvement in MMDTP. Figure 13 shows a qualitative comparison of the predicted instance shapes as PCs. Note that the visible portion of the instances varies from one to another, but our
\({\mathscr {E}}\) can reliably infer the invisible surface. Figure 14 shows the relationship between MMDTP with factors such as object depth and bounding box quality. More distant objects
and less accurate 3D bounding boxes suffer from larger MMD for81 due to fewer visible points and larger alignment errors. Note that our approach consistently improves81 across different
depth ranges and box proposal quality levels. Per our definition of \(AP_{MMD}\), the \(s_{MMD}\) at different recall values are shown in Fig. 15 for the predictions of Disp-RCNN. In
contrast, the performance of using our \({\mathscr {E}}\) for the same proposals is shown in Fig. 16. The detailed quantitative results are shown in Tab. 7. The \(AP_{2D}\) (IoU > 0.7),
i.e., the upper bound for \(AP_{MMD}\), is 99.16, 93.22, 81.28 for easy, moderate, and hard categories respectively. Note our \({\mathscr {E}}\) has contributed a significant improvement
compared with81. This indicates our approach has greatly complemented existing 3DOD approaches with the ability to describe outdoor object surface geometry within the 3D bounding boxes.
ABLATION STUDY DIRECT REGRESSION VS. LEARNING IGRS. To validate the design of our proposed IGRs for orientation estimation, we compare the pose estimation accuracy of our approach to a
baseline that directly regresses pose angles from the instance feature maps. To eliminate the impact of the used object detector, we compare _AOS_ on all annotated vehicle instances in the
validation set. This is equivalent to measuring _AOS_ with \(AP_{2D}=1\) so that the orientation estimation accuracy becomes the only focus. The comparison is summarized in Table 8. Note
learning IGRs outperforms the baseline by a significant margin. Deep3DBox4 is another popular architecture that performs direct angle regression. Our approach outperforms it with the novel
design of IGRs. IS PPCS BETTER THAN THE SINGLE-VIEW REPRESENTATION? Table 9 shows the performance comparison between single-view Ego-Net and Ego-Net++ that uses stereo inputs. Using PPCs
leads to better performance and validates the improvement of Ego-Net++ over Ego-Net. It also validates the coordinate representations designed in this study can be used easily with
multi-view inputs. IS _Ha_ USEFUL? Hereafter we use the same object proposals as used in Table 3 for consistency. We compare the performance without _Ha_ in Table 10, where the normalized
representation _ocsi_ is directly used for evaluation before being passed to _Ha_. The results indicate _Ha_ effectively hallucinates plausible points to provide a complete shape
representation. CONCLUSION We propose the first approach for joint stereo 3D object detection and implicit shape reconstruction with a new two-stage model S-3D-RCNN. S-3D-RCNN can (1)
perform accurate object localization as well as provide a complete and resolution-agnostic shape description for the detected rigid objects and (2) produce significantly more accurate
orientation predictions. To address the challenging problem of 3D attribute estimation from images, a set of new intermediate geometrical representations are designed and validated.
Experiments show that S-3D-RCNN achieves strong image-based 3D scene understanding capability and brings new opportunities for outdoor augmented reality. Our framework can be extended to
non-rigid shape estimation if corresponding data is available to train our hallucination module. How to devise an effective training approach to achieve stereo pedestrian reconstruction is
an interesting research question which we leave for future work. DATA AVAILABILITY The datasets generated during and/or analyzed during our study are available from the corresponding author
on reasonable request. REFERENCES * Marr, D. _Vision: A Computational Investigation into the Human Representation and Processing of Visual Information, 32–33_ (MIT press, 2010). Book Google
Scholar * Ferryman, J. M., Maybank, S. J. & Worrall, A. D. Visual surveillance for moving vehicles. _Int. J. Comput. Vision_ 37, 187–197 (2000). Article Google Scholar * Yang, B.,
Bai, M., Liang, M., Zeng, W. & Urtasun, R. Auto4d: Learning to label 4d objects from sequential point clouds. arXiv:2101.06586 (2021). * Mousavian, A., Anguelov, D., Flynn, J. &
Kosecka, J. 3d bounding box estimation using deep learning and geometry. _CVPR_ 2017, 7074–7082 (2017). Google Scholar * Brazil, G. & Liu, X. M3d-rpn: Monocular 3d region proposal
network for object detection. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ 9287–9296 (2019). * Li, S., Yan, Z., Li, H. & Cheng, K.-T. Exploring
intermediate representation for monocular vehicle pose estimation. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 1873–1883 (2021). * Geiger, A.,
Lenz, P. & Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_
3354–3361 (IEEE, 2012). * Hoiem, D., Efros, A. A. & Hebert, M. Closing the loop in scene interpretation. In _2008 IEEE Conference on Computer Vision and Pattern Recognition_ 1–8 (IEEE,
2008). * Geiger, A., Wojek, C. & Urtasun, R. Joint 3d estimation of objects and scene layout. _Adv. Neural. Inf. Process. Syst._ 24, 1467–1475 (2011). Google Scholar * Kim, B.-S.,
Kohli, P. & Savarese, S. 3d scene understanding by voxel-crf. In _Proceedings of the IEEE International Conference on Computer Vision_ 1425–1432 (2013). * Zhang, Y., Song, S., Tan, P.
& Xiao, J. Panocontext: A whole-room 3d context model for panoramic scene understanding. In _European conference on computer vision_ 668–686 (Springer, 2014). * Tulsiani, S., Gupta, S.,
Fouhey, D. F., Efros, A. A. & Malik, J. Factoring shape, pose, and layout from the 2d image of a 3d scene. In _Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition_ 302–310 (2018). * Chen, Y. _et al._ Holistic++ scene understanding: Single-view 3d holistic scene parsing and human pose estimation with human-object interaction and physical
commonsense. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ 8648–8657 (2019). * Hampali, S. _et al._ Monte carlo scene search for 3d scene understanding. In
_Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 13804–13813 (2021). * Dahnert, M., Hou, J., Nießner, M. & Dai, A. Panoptic 3d scene reconstruction
from a single rgb image. In _Proc. Neural Information Processing Systems (NeurIPS)_ (2021). * Yuille, A. & Kersten, D. Vision as bayesian inference: Analysis by synthesis?. _Trends Cogn.
Sci._ 10, 301–308 (2006). Article PubMed Google Scholar * Loper, M. M. & Black, M. J. Opendr: An approximate differentiable renderer. In _European Conference on Computer Vision_
154–169 (Springer, 2014). * Niemeyer, M., Mescheder, L., Oechsle, M. & Geiger, A. Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In
_Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 3504–3515 (2020). * Zakharov, S. _et al._ Single-shot scene reconstruction. In _5th Annual Conference on
Robot Learning_ (2021). * Eslami, S. _et al._ Attend, infer, repeat: Fast scene understanding with generative models. _Adv. Neural. Inf. Process. Syst._ 29, 3225–3233 (2016). Google Scholar
* Chabot, F., Chaouch, M., Rabarisoa, J., Teuliere, C. & Chateau, T. Deep manta: A coarse-to-fine many-task network for joint 2d and 3d vehicle analysis from monocular image. In
_Proceedings of the IEEE conference on computer vision and pattern recognition_ 2040–2049 (2017). * Kundu, A., Li, Y. & Rehg, J. M. 3d-rcnn: Instance-level 3d object reconstruction via
render-and-compare. In _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_ 3559–3568 (2018). * Engelmann, F., Rematas, K., Leibe, B. & Ferrari, V. From points
to multi-object 3d reconstruction. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 4588–4597 (2021). * Schwing, A. G. & Urtasun, R. Efficient
exact inference for 3d indoor scene understanding. In _European conference on computer vision_ 299–313 (Springer, 2012). * Nie, Y. _et al._ Total3dunderstanding: Joint layout, object pose
and mesh reconstruction for indoor scenes from a single image. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 55–64 (2020). * Runz, M. _et al._ Frodo:
From detections to 3d objects. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 14720–14729 (2020). * Zhang, C. _et al._ Deeppanocontext: Panoramic 3d
scene understanding with holistic scene context graph and relation-based optimization. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ 12632–12641 (2021). * Liu,
F. & Liu, X. Voxel-based 3d detection and reconstruction of multiple objects from a single image. In _In Proceeding of Thirty-fifth Conference on Neural Information Processing Systems_
(Virtual, 2021). * Huang, S. _et al._ Holistic 3d scene parsing and reconstruction from a single rgb image. In _Proceedings of the European conference on computer vision (ECCV)_ 187–203
(2018). * Gkioxari, G., Malik, J. & Johnson, J. Mesh r-cnn. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ 9785–9795 (2019). * Mustafa, A., Caliskan, A.,
Agapito, L. & Hilton, A. Multi-person implicit reconstruction from a single image. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 14474–14483
(2021). * Song, R., Zhang, W., Zhao, Y., Liu, Y. & Rosin, P. L. 3d visual saliency: An independent perceptual measure or a derivative of 2d image saliency?. _IEEE Trans. Pattern Anal.
Mach. Intell._ 45, 13083–13099. https://doi.org/10.1109/TPAMI.2023.3287356 (2023). Article PubMed Google Scholar * Wang, D. _et al._ Multi-view 3d reconstruction with transformers. In
_2021 IEEE/CVF International Conference on Computer Vision (ICCV)_ 5702–5711. https://doi.org/10.1109/ICCV48922.2021.00567 (2021). * Chen, X. _et al._ 3d object proposals for accurate object
class detection. In _Advances in Neural Information Processing Systems_ 424–432 (Citeseer, 2015). * Simonelli, A., Bulo, S. R., Porzi, L., López-Antequera, M. & Kontschieder, P.
Disentangling monocular 3d object detection. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ 1991–1999 (2019). * Zhou, D. _et al._ Iafa: Instance-aware feature
aggregation for 3d object detection from a single image. In _Proceedings of the Asian Conference on Computer Vision_ (2020). * Reading, C., Harakeh, A., Chae, J. & Waslander, S. L.
Categorical depth distribution network for monocular 3d object detection. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 8555–8564 (2021). * Lian, Q.,
Ye, B., Xu, R., Yao, W. & Zhang, T. Exploring geometric consistency for monocular 3d object detection. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition_ 1685–1694 (2022). * Chen, Y.-N., Dai, H. & Ding, Y. Pseudo-stereo for monocular 3d object detection in autonomous driving. In _Proceedings of the IEEE/CVF Conference on
Computer Vision and Pattern Recognition_ 887–897 (2022). * Yan, Y., Mao, Y. & Li, B. Second: Sparsely embedded convolutional detection. _Sensors_ 18, 3337 (2018). Article ADS PubMed
PubMed Central Google Scholar * Zhou, Y. & Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In _Proceedings of the IEEE conference on computer vision
and pattern recognition_ 4490–4499 (2018). * Shi, S., Wang, X. & Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In _Proceedings of the IEEE/CVF
conference on computer vision and pattern recognition_ 770–779 (2019). * Shi, S. _et al._ Pv-rcnn++: Point-voxel feature set abstraction with local vector representation for 3d object
detection. arXiv:2102.00463 (2021). * Juranek, R., Herout, A., Dubská, M. & Zemcik, P. Real-time pose estimation piggybacked on object detection. In _Proceedings of the IEEE
International Conference on Computer Vision_ 2381–2389 (2015). * Xiang, Y., Choi, W., Lin, Y. & Savarese, S. Data-driven 3d voxel patterns for object category recognition. In
_Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_ 1903–1911 (2015). * Dollár, P., Appel, R., Belongie, S. & Perona, P. Fast feature pyramids for object
detection. _IEEE Trans. Pattern Anal. Mach. Intell._ 36, 1532–1545 (2014). Article PubMed Google Scholar * Yang, L., Liu, J. & Tang, X. Object detection and viewpoint estimation with
auto-masking neural network. In _European conference on computer vision_ 441–455 (Springer, 2014). * Zhou, Y., Liu, L., Shao, L. & Mellor, M. Dave: A unified framework for fast vehicle
detection and annotation. In _European Conference on Computer Vision_ 278–293 (Springer, 2016). * Zhou, Y., Liu, L., Shao, L. & Mellor, M. Fast automatic vehicle annotation for urban
traffic surveillance. _IEEE Trans. Intell. Transp. Syst._ 19, 1973–1984 (2017). Article Google Scholar * Braun, M., Rao, Q., Wang, Y. & Flohr, F. Pose-rcnn: Joint object detection and
pose estimation using 3d object proposals. In _2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC)_ 1546–1551 (IEEE, 2016). * Chen, X. _et al._ 3d object
proposals using stereo imagery for accurate object class detection. _IEEE Trans. Pattern Anal. Mach. Intell._ 40, 1259–1272 (2017). Article PubMed Google Scholar * Huang, S. _et al._
Perspectivenet: 3d object detection from a single rgb image via perspective points. arXiv:1912.07744 (2019). * Ke, L., Li, S., Sun, Y., Tai, Y.-W. & Tang, C.-K. Gsnet: Joint vehicle pose
and shape reconstruction with geometrical and scene-aware supervision. In _European Conference on Computer Vision_ 515–532 (Springer, 2020). * Liu, X. _et al._ Conservative wasserstein
training for pose estimation. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ 8262–8272 (2019). * Liu, L., Lu, J., Xu, C., Tian, Q. & Zhou, J. Deep fitting
degree scoring network for monocular 3d object detection. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 1057–1066 (2019). * Peng, W., Pan, H., Liu,
H. & Sun, Y. Ida-3d: Instance-depth-aware 3d object detection from stereo vision for autonomous driving. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition_ 13015–13024 (2020). * Liu, L. _et al._ Reinforced axial refinement network for monocular 3d object detection. In _European Conference on Computer Vision_ 540–556 (Springer,
2020). * Park, J. J., Florence, P., Straub, J., Newcombe, R. & Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In _Proceedings of the
IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 165–174 (2019). * Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S. & Geiger, A. Occupancy networks: Learning 3d
reconstruction in function space. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 4460–4470 (2019). * Chabra, R. _et al._ Deep local shapes: Learning
local sdf priors for detailed 3d reconstruction. In _European Conference on Computer Vision_ 608–625 (Springer, 2020). * Erler, P., Guerrero, P., Ohrhallinger, S., Mitra, N. J. & Wimmer,
M. Points2surf learning implicit surfaces from point clouds. In _European Conference on Computer Vision_ 108–124 (Springer, 2020). * Takikawa, T. _et al._ Neural geometric level of detail:
Real-time rendering with implicit 3d shapes. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 11358–11367 (2021). * Chen, Y., Liu, S., Shen, X. &
Jia, J. Dsgn: Deep stereo geometry network for 3d object detection. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 12536–12545 (2020). * Ding, M. _et
al._ Learning depth-guided convolutions for monocular 3d object detection. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops_ 1000–1001 (2020).
* Tompson, J. J., Jain, A., LeCun, Y. & Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. _Adv. Neural Inf. Process. Syst._ 27, 896
(2014). Google Scholar * Zeeshan Zia, M., Stark, M. & Schindler, K. Are cars just 3d boxes?-jointly estimating the 3d shape of multiple objects. In _Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition_ 3678–3685 (2014). * Engelmann, F., Stückler, J. & Leibe, B. Joint object pose estimation and shape reconstruction in urban street scenes using
3d shape priors. In _German Conference on Pattern Recognition_ 219–230 (Springer, 2016). * Chen, L. _et al._ Shape prior guided instance disparity estimation for 3d object detection. _IEEE
Trans. Pattern Anal. Mach. Intell._ 2021, 237 (2021). Google Scholar * Qi, C. R., Su, H., Mo, K. & Guibas, L. J. Pointnet: Deep learning on point sets for 3d classification and
segmentation. In _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_ 652–660 (2017). * Lorensen, W. E. & Cline, H. E. Marching cubes: A high resolution 3d
surface construction algorithm. _ACM Siggraph Comput. Graph._ 21, 163–169 (1987). Article Google Scholar * Chang, A. X. _et al._ Shapenet: An information-rich 3d model repository.
arXiv:1512.03012 (2015). * Yuan, W., Khot, T., Held, D., Mertz, C. & Hebert, M. Pcn: Point completion network. In _2018 International Conference on 3D Vision (3DV)_ 728–737 (IEEE, 2018).
* Yu, X. _et al._ Pointr: Diverse point cloud completion with geometry-aware transformers. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ 12498–12507 (2021). *
Caesar, H. _et al._ nuscenes: A multimodal dataset for autonomous driving. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 11621–11631 (2020). * Ku,
J., Pon, A. D. & Waslander, S. L. Monocular 3d object detection leveraging accurate proposals and shape reconstruction. In _CVPR_ 11867–11876 (2019). * Brazil, G., Pons-Moll, G., Liu, X.
& Schiele, B. Kinematic 3d object detection in monocular video. In _In Proceeding of European Conference on Computer Vision_ (Virtual, 2020). * Chen, X. _et al._ Monocular 3d object
detection for autonomous driving. In _Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition_ 2147–2156 (2016). * Xu, B. & Chen, Z. Multi-level fusion based 3d
object detection from monocular images. In _CVPR_ 2345–2353 (2018). * Li, B., Ouyang, W., Sheng, L., Zeng, X. & Wang, X. Gs3d: An efficient 3d object detection framework for autonomous
driving. In _CVPR_ 1019–1028 (2019). * Chen, Y., Tai, L., Sun, K. & Li, M. Monopair: Monocular 3d object detection using pairwise spatial relationships. In _Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recognition_ 12093–12102 (2020). * Sun, J. _et al._ Disp r-cnn: Stereo 3d object detection via shape prior guided instance disparity estimation. In
_Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 10548–10557 (2020). * Li, P., Zhao, H., Liu, P. & Cao, F. Rtm3d: Real-time monocular 3d detection from
object keypoints for autonomous driving. In _European Conference on Computer Vision_ 644–660 (Springer, 2020). * Lang, A. H. _et al._ Pointpillars: Fast encoders for object detection from
point clouds. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_ 12697–12705 (2019). * Lu, Y. _et al._ Geometry uncertainty projection network for
monocular 3d object detection. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ 3111–3121 (2021). * Liu, Z. _et al._ Tanet: Robust 3d object detection from point
clouds with triple attention. In _Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34_ 11677–11684 (2020). * Liu, Y., Wang, L. & Liu, M. Yolostereo3d: A step back to
2d for efficient stereo 3d detection. In _2021 International Conference on Robotics and Automation (ICRA)_ (IEEE, 2021). * Zhou, Y. _et al._ Monocular 3d object detection: An extrinsic
parameter free approach. In _Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)_ 7556–7566 (2021). * Guo, X., Shi, S., Wang, X. & Li, H.
Liga-stereo: Learning lidar geometry aware representations for stereo-based 3d detector. In _Proceedings of the IEEE/CVF International Conference on Computer Vision_ 3153–3163 (2021). *
Xianpeng Liu, T. W. & Nan, X. Learning auxiliary monocular contexts helps monocular 3d object detection. In _AAAI_ (2022). * Peng, L., Liu, F., Yan, S., He, X. & Cai, D. Ocm3d:
Object-centric monocular 3d object detection. arXiv:2104.06041 (2021). * Manhardt, F., Kehl, W. & Gaidon, A. Roi-10d: Monocular lifting of 2d detection to 6d pose and metric shape. In
_CVPR_ 2069–2078 (2019). * He, T. & Soatto, S. Mono3d++: Monocular 3d vehicle detection with two-scale 3d hypotheses and task priors. In _In Proceedings of the AAAI Conference on
Artificial Intelligence, vol. 33_ 8409–8416 (2019). Download references AUTHOR INFORMATION Author notes * These authors contributed equally: Xijie Huang and Zechun Liu. AUTHORS AND
AFFILIATIONS * Department of Computer Science and Engineering, HKUST, Hong Kong, SAR, 999077, China Shichao Li, Xijie Huang & Kwang-Ting Cheng * Meta Reality Labs, Pittsburgh, 15222, USA
Zechun Liu Authors * Shichao Li View author publications You can also search for this author inPubMed Google Scholar * Xijie Huang View author publications You can also search for this
author inPubMed Google Scholar * Zechun Liu View author publications You can also search for this author inPubMed Google Scholar * Kwang-Ting Cheng View author publications You can also
search for this author inPubMed Google Scholar CONTRIBUTIONS S.Li. conceived the experiment(s), S.Li. conducted the experiment(s), X.Huang. and Z.Liu. analysed the results. All authors
reviewed the manuscript. CORRESPONDING AUTHOR Correspondence to Shichao Li. ETHICS DECLARATIONS COMPETING INTERESTS The authors declare no competing interests. ADDITIONAL INFORMATION
PUBLISHER'S NOTE Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. SUPPLEMENTARY INFORMATION SUPPLEMENTARY
INFORMATION. RIGHTS AND PERMISSIONS OPEN ACCESS This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution
and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if
changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the
material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to
obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. Reprints and permissions ABOUT THIS ARTICLE CITE THIS
ARTICLE Li, S., Huang, X., Liu, Z. _et al._ Joint stereo 3D object detection and implicit surface reconstruction. _Sci Rep_ 14, 13893 (2024). https://doi.org/10.1038/s41598-024-64677-2
Download citation * Received: 10 March 2024 * Accepted: 12 June 2024 * Published: 17 June 2024 * DOI: https://doi.org/10.1038/s41598-024-64677-2 SHARE THIS ARTICLE Anyone you share the
following link with will be able to read this content: Get shareable link Sorry, a shareable link is not currently available for this article. Copy to clipboard Provided by the Springer
Nature SharedIt content-sharing initiative
Trending News
Latest news, breaking news, live news, top news headlines, viral video, cricket live, sports, entertainment, business, health, lifestyle and utility nLatest News, Breaking News, LIVE News, Top News Headlines, Viral Video, Cricket LIVE, Sports, Entertainment, Business, H...
Characterization of human oxidoreductases involved in aldehyde odorant metabolismABSTRACT Oxidoreductases are major enzymes of xenobiotic metabolism. Consequently, they are essential in the chemoprotec...
Patches of greenIt is introspection time. As the country's forest bureaucracy sits down to assess the progress of the joint forest ...
Flight secrets: best plane seat revealed to prevent sicknessFlights are nothing to be afraid of and planes are known to be one of the safest modes of transport. Many nervous flyers...
LaLiga Hypermotion - AS.comReal ZaragozaEl Zaragoza tiene un 92,59% de probabilidades de permanenciaJavier Marín...
Latests News
Joint stereo 3d object detection and implicit surface reconstructionABSTRACT We present a new learning-based framework S-3D-RCNN that can recover accurate object orientation in SO(3) and s...
Lebron james reaches billionaire statusLeBron James reaches billionaire status | WTVB | 1590 AM · 95.5 FM | The Voice of Branch County Close For the health and...
What to Say When You Have Been Exposed to COVID2:13 Videos de AARP What to Say When You Have Been Exposed to COVID Facebook Twitter LinkedIn Finding out that you’ve be...
6 things that frustrate older players of video gamesMemorial Day Sale! Join AARP for just $11 per year with a 5-year membership Join now and get a FREE gift. Expires 6/4 G...
2019 aarp community challenge grantee - bennington, vermontMemorial Day Sale! Join AARP for just $11 per year with a 5-year membership Join now and get a FREE gift. Expires 6/4 G...